전체적으로 고르게 분포되어 있습니다. 연속 확률 변수의 균일 및 지수 분포 법칙
이를 통해 많은 실제 프로세스가 시뮬레이션됩니다. 그리고 가장 일반적인 예는 대중교통 시간표입니다. 어떤 버스가 있다고 가정해보자. (무궤도전차/트램) 10분마다 운행하며, 임의의 순간에 정차합니다. 버스가 1분 안에 도착할 확률은 얼마입니까? 물론 1/10입니다. 4~5분 정도 기다려야 할 확률은 얼마나 됩니까? 같은 . 버스를 9분 이상 기다려야 할 확률은 얼마입니까? 10분의 1!
몇 가지를 고려해 봅시다 한정된간격, 명확성을 위해 세그먼트라고 가정합니다. 만약에 무작위 변수가지다 끊임없는 확률 분포 밀도주어진 세그먼트에 있고 그 외부의 밀도가 0이면 분산되어 있다고 말합니다. 고르게. 이 경우 밀도 함수는 엄격하게 정의됩니다. 
실제로 세그먼트의 길이가 길면 (그림 참조)이면 값은 필연적으로 동일하므로 직사각형의 단위 면적이 얻어지고 관찰됩니다. 알려진 속성:
공식적으로 확인해 봅시다:
, 등. 확률론적 관점에서 이는 확률변수가 확실하게세그먼트의 가치 중 하나를 취할 것입니다..., 어, 점점 지루한 노인이 되어가고 있습니다 =)
균일성의 본질은 내부의 틈이 무엇이든 간에 고정 길이우리는 고려하지 않았습니다 (“버스”분을 기억하세요)– 확률변수가 이 구간에서 값을 취할 확률은 동일합니다. 그림에서 나는 그러한 확률 세 가지를 음영 처리했습니다. 다시 한 번 강조합니다. 지역에 따라 결정됩니다, 함수 값이 아닙니다!
일반적인 작업을 고려해 보겠습니다.
실시예 1
연속 확률 변수는 분포 밀도로 지정됩니다. ![]()
상수를 찾고, 분포 함수를 계산하고 구성합니다. 그래프를 작성하세요. 찾다
즉, 당신이 꿈꾸는 모든 것 :)
해결책: 간격 이후 (유한한 간격) ![]() 이면 확률변수는 균일한 분포를 가지며 직접 공식을 사용하여 "ce"의 값을 찾을 수 있습니다.
이면 확률변수는 균일한 분포를 가지며 직접 공식을 사용하여 "ce"의 값을 찾을 수 있습니다. ![]() . 하지만 일반적인 방법으로는 더 좋습니다 - 속성을 사용하면:
. 하지만 일반적인 방법으로는 더 좋습니다 - 속성을 사용하면:
...왜 더 좋아졌나요? 불필요한 질문이 없도록;)
따라서 밀도 함수는 다음과 같습니다. 
그림을 그려보자. 가치 불가능한
, 따라서 굵은 점은 아래에 배치됩니다. 
빠른 확인을 위해 직사각형의 면적을 계산해 보겠습니다. ![]() , 등.
, 등.
찾아보자 수학적 기대, 그리고 당신은 아마도 그것이 무엇과 같은지 이미 추측할 수 있을 것입니다. "10분" 버스를 기억하세요. 무작위로여러 날 동안 정류장에 접근하다가 평균적으로당신은 그를 5분 동안 기다려야 할 것이다.
예, 맞습니다. 기대값은 정확히 "이벤트" 간격의 중간에 있어야 합니다.
, 예상대로.
다음을 사용하여 분산을 계산해 보겠습니다. 공식 ![]() . 그리고 적분을 계산할 때 눈과 눈이 필요합니다.
. 그리고 적분을 계산할 때 눈과 눈이 필요합니다.
따라서, 분산: ![]()
작곡하자 분포 함수 ![]() . 여기에는 새로운 것이 없습니다.
. 여기에는 새로운 것이 없습니다.
1) 만약 , 그렇다면 그리고 ![]() ;
;
2) if , then 그리고:
3) 그리고 마지막으로, 언제 ![]() , 그 이유는 다음과 같습니다.
, 그 이유는 다음과 같습니다.
결과적으로: 
그림을 그려보자: 
"실시간" 간격에서 분포 함수는 성장하는 선의, 이는 균일하게 분포된 확률 변수가 있다는 또 다른 신호입니다. 물론 결국엔 유도체 선형 함수- 상수가 있습니다.
필요한 확률은 발견된 분포 함수를 사용하여 두 가지 방법으로 계산할 수 있습니다.
또는 특정 밀도 적분을 사용하여: 
누구든지 그것을 좋아합니다.
그리고 여기에 쓸 수도 있습니다 답변: , , 그래프는 솔루션을 따라 작성됩니다.
, 그래프는 솔루션을 따라 작성됩니다.
... 일반적으로 부재에 대한 처벌이 없기 때문에 "가능합니다". 대개;)
균일확률변수를 계산하는 특별한 공식이 있는데, 이를 직접 도출해 보시기 바랍니다.
실시예 2
연속 확률 변수는 밀도로 제공됩니다.  .
.
수학적 기대값과 분산을 계산합니다. 결과를 최대한 단순화하세요. (약식 곱셈 공식도움을 주기 위해).
결과 공식은 특히 "a"와 "b"의 특정 값을 대입하여 방금 해결한 문제를 확인하는 데 편리합니다. 페이지 하단에 간단한 솔루션이 있습니다.
그리고 수업이 끝나면 몇 가지 "텍스트" 문제를 살펴보겠습니다.
실시예 3
측정 장치의 눈금 분할 값은 0.2입니다. 기기 판독값은 가장 가까운 전체 눈금으로 반올림됩니다. 반올림 오류가 균일하게 분포되어 있다고 가정하고 다음 측정에서 0.04를 초과하지 않을 확률을 구하십시오.
더 나은 이해를 위해 솔루션이것이 화살표가 있는 일종의 기계 장치(예: 분할 값이 0.2kg인 저울)이고 돼지의 무게를 찔러야 한다고 가정해 보겠습니다. 그러나 그의 비만을 알아 내기 위해서가 아닙니다. 이제 화살표가 인접한 두 구분선 사이에서 멈추는 위치가 중요합니다.
무작위 변수를 고려해 봅시다 - 거리화살표 가장 가까운좌파. 아니면 가장 가까운 오른쪽부터 상관없습니다.
확률 밀도 함수를 구성해 보겠습니다.
1) 거리는 음수가 될 수 없으므로 간격은 입니다. 논리적.
2) 조건에 따라 비늘의 화살표는 다음과 같습니다. 동등한 확률디비전 사이 어디에서나 중지할 수 있습니다. *
, 분할 자체를 포함하므로 간격에 따라 다음과 같습니다. ![]()
* 이는 필수 조건입니다. 예를 들어, 탈지면 조각이나 소금 1kg 팩의 무게를 측정할 때 균일성은 훨씬 더 좁은 간격으로 유지됩니다.
3) 그리고 NEAREST 왼쪽 분할로부터의 거리는 0.2보다 클 수 없으므로 at도 0과 같습니다.
따라서: 
아무도 우리에게 밀도 함수에 대해 물어보지 않았고, 나는 그것의 완전한 구성을 인지 사슬에서만 제시했다는 점에 유의해야 합니다. 작업을 완료할 때 두 번째 항목만 적으면 충분합니다.
이제 문제의 질문에 답해 보겠습니다. 가장 가까운 눈금으로 반올림할 때 오류가 0.04를 초과하지 않는 경우는 언제입니까? 이는 화살표가 왼쪽 구분선에서 0.04 이상 떨어지지 않을 때 발생합니다. 오른쪽 또는오른쪽 분할에서 0.04 이하 왼쪽. 그림에서 해당 영역을 음영 처리했습니다. 
이 영역을 찾는 것이 남아 있습니다. 적분을 사용하여. 원칙적으로는 "학교 방식"(예: 직사각형 영역)으로 계산할 수 있지만 단순성이 항상 이해되는 것은 아닙니다.)
에 의해 양립할 수 없는 사건의 확률 덧셈의 정리:
– 반올림 오류가 0.04(이 예에서는 40g)를 초과하지 않을 확률
가능한 최대 반올림 오류는 0.1(100g)이라는 것을 쉽게 알 수 있습니다. 반올림 오류가 0.1을 초과하지 않을 확률 1과 같습니다.
답변: 0,4
다른 정보 출처에는 이 문제에 대한 대안적인 설명/공식이 있으며, 나는 나에게 가장 이해하기 쉬운 옵션을 선택했습니다. 특별한 관심조건에서 반올림이 아닌 오류에 대해 이야기할 수 있다는 사실에 주의할 필요가 있습니다. 무작위의측정 오류는 일반적으로 (항상은 아니지만), 배포자: 보통법. 따라서, 단 한 단어만으로도 결정이 근본적으로 바뀔 수 있습니다!주의를 기울여 그 의미를 이해하십시오.
그리고 모든 것이 원을 그리자마자 우리의 발은 우리를 같은 버스 정류장으로 데려다줍니다.
실시예 4
특정 노선의 버스는 엄격하게 일정에 따라 7분 간격으로 운행됩니다. 무작위 변수의 밀도 함수, 즉 무작위로 정류장에 접근한 승객이 다음 버스를 기다리는 시간을 구성합니다. 그가 버스를 3분 이상 기다릴 확률을 구하여라. 분포함수를 찾고 그 의미를 설명하시오.
연속 확률 변수의 예로, 구간 (a; b)에 균일하게 분포된 확률 변수 X를 생각해 보세요. 확률변수 X는 다음과 같다. 고르게 분포 구간 (a; b)에서 분포 밀도가 이 구간에서 일정하지 않은 경우:
정규화 조건에서 상수 c의 값을 결정합니다. 분포 밀도 곡선 아래의 면적은 1과 같아야 하지만 우리의 경우 밑면(b - α)과 높이 c가 있는 직사각형의 면적입니다(그림 1). 
쌀. 1 균일한 분포 밀도
여기에서 상수 c의 값을 찾습니다. ![]()
따라서 균일하게 분포된 확률 변수의 밀도는 다음과 같습니다. 
이제 다음 공식을 사용하여 분포 함수를 찾아보겠습니다.
1) ![]()
2)
3) 0+1+0=1의 경우.
따라서, 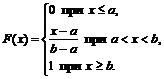
분포함수는 연속적이며 감소하지 않습니다(그림 2). 
쌀. 2 균일하게 분포된 확률 변수의 분포 함수
우리는 찾을 것이다 균일하게 분포된 확률 변수의 수학적 기대공식에 따르면:
균일한 분포의 분산공식으로 계산되며 다음과 같습니다.
예 1. 측정 장치의 눈금 분할 값은 0.2입니다. 기기 판독값은 가장 가까운 전체 눈금으로 반올림됩니다. 계산 중에 오류가 발생할 확률을 찾으십시오. a) 0.04 미만; b) 큰 0.02
해결책. 반올림 오류는 인접한 정수 나누기 사이의 간격에 균일하게 분포된 확률 변수입니다. 간격(0; 0.2)을 그러한 구분으로 생각해 보겠습니다(그림 a). 반올림은 왼쪽 경계(0)와 오른쪽 방향(0.2) 모두에서 수행할 수 있습니다. 즉, 0.04보다 작거나 같은 오류가 두 번 발생할 수 있으며 확률을 계산할 때 고려해야 합니다. 

P = 0.2 + 0.2 = 0.4
두 번째 경우 오류 값은 두 분할 경계 모두에서 0.02를 초과할 수 있습니다. 즉, 0.02보다 크거나 0.18보다 작을 수 있습니다. 
그러면 다음과 같은 오류가 발생할 가능성이 있습니다.
예 2. 지난 50년간 국가 경제 상황(전쟁, 자연재해 없음)의 안정성은 연령별 인구 분포 특성으로 판단할 수 있다고 가정했습니다. 제복. 연구 결과, 한 국가에 대해 다음과 같은 데이터를 얻었습니다.
국가가 불안정했다고 믿을 만한 이유가 있나요?우리는 가설 테스트를 사용하여 솔루션을 수행합니다.. 지표 계산 표.
| 여러 떼 | 구간의 중간점, x i | 수량, f i | x 나는 * f 나는 | 누적 주파수, S | |x - x 평균 |*f | (x - x 평균) 2 *f | 주파수, f i /n |
| 0 - 10 | 5 | 0.14 | 0.7 | 0.14 | 5.32 | 202.16 | 0.14 |
| 10 - 20 | 15 | 0.09 | 1.35 | 0.23 | 2.52 | 70.56 | 0.09 |
| 20 - 30 | 25 | 0.1 | 2.5 | 0.33 | 1.8 | 32.4 | 0.1 |
| 30 - 40 | 35 | 0.08 | 2.8 | 0.41 | 0.64 | 5.12 | 0.08 |
| 40 - 50 | 45 | 0.16 | 7.2 | 0.57 | 0.32 | 0.64 | 0.16 |
| 50 - 60 | 55 | 0.13 | 7.15 | 0.7 | 1.56 | 18.72 | 0.13 |
| 60 - 70 | 65 | 0.12 | 7.8 | 0.82 | 2.64 | 58.08 | 0.12 |
| 70 - 80 | 75 | 0.18 | 13.5 | 1 | 5.76 | 184.32 | 0.18 |
| 1 | 43 | 20.56 | 572 | 1 |
가중평균
변형 표시기.
절대 변형.
변동 범위는 1차 계열 특성의 최대값과 최소값의 차이입니다.
R = X 최대 - X 최소
R = 70 - 0 = 70
분산- 평균값 주변의 분산 측정값을 특성화합니다(분산 측정값, 즉 평균과의 편차).
표준편차.
계열의 각 값은 평균값 43과 23.92 이하로 다릅니다.
분포 유형에 대한 가설 테스트.
4. 가설 검증 균일한 분포일반 인구.
X의 균일 분포에 대한 가설을 테스트하기 위해, 즉 법칙에 따르면: 구간 (a,b)에서 f(x) = 1/(b-a)
필요한:
1. 공식을 사용하여 가능한 X 값이 관찰된 간격의 끝인 매개변수 a와 b를 추정합니다(* 기호는 매개변수 추정치를 나타냄).
2. 예상 분포 f(x) = 1/(b * - a *)의 확률 밀도를 구합니다.
3. 이론적 주파수를 찾으십시오.
n 1 = nP 1 = n = n*1/(b * - a *)*(x 1 - a *)
n 2 = n 3 = ... = n s-1 = n*1/(b * - a *)*(x i - x i-1)
n s = n*1/(b * - a *)*(b * - x s-1)
4. 자유도 k = s-3을 취하여 Pearson 기준을 사용하여 경험적 빈도와 이론적 빈도를 비교합니다. 여기서 s는 초기 샘플링 간격의 수입니다. 작은 빈도의 조합, 즉 간격 자체가 수행된 경우 s는 조합 후 남은 간격의 수입니다.
해결책:
1. 다음 공식을 사용하여 균일 분포의 모수 a * 및 b * 추정치를 찾습니다.
2. 가정된 균일 분포의 밀도를 찾으십시오.
f(x) = 1/(b * - a *) = 1/(84.42 - 1.58) = 0.0121
3. 이론적인 주파수를 찾아봅시다:
n 1 = n*f(x)(x 1 - a *) = 1 * 0.0121(10-1.58) = 0.1
n 8 = n*f(x)(b * - x 7) = 1 * 0.0121(84.42-70) = 0.17
나머지 n 은 다음과 같습니다.
ns = n*f(x)(xi - xi-1)
| 나 | 아니 나는 | n*i | n 나는 - n * 나는 | (n i - n* i) 2 | (n i - n * i) 2 /n * i |
| 1 | 0.14 | 0.1 | 0.0383 | 0.00147 | 0.0144 |
| 2 | 0.09 | 0.12 | -0.0307 | 0.000943 | 0.00781 |
| 3 | 0.1 | 0.12 | -0.0207 | 0.000429 | 0.00355 |
| 4 | 0.08 | 0.12 | -0.0407 | 0.00166 | 0.0137 |
| 5 | 0.16 | 0.12 | 0.0393 | 0.00154 | 0.0128 |
| 6 | 0.13 | 0.12 | 0.0093 | 8.6E-5 | 0.000716 |
| 7 | 0.12 | 0.12 | -0.000701 | 0 | 4.0E-6 |
| 8 | 0.18 | 0.17 | 0.00589 | 3.5E-5 | 0.000199 |
| 총 | 1 | 0.0532 |
따라서 이러한 통계의 중요한 영역은 항상 오른 손잡이입니다. :)








