Найти линейный тренд для ряда. Методы определения параметров уравнения тренда
Покажем пример подробного расчета параметров уравнения тренда на основе следующих данных (см. таблицу) с использованием калькулятора .
Линейное уравнение тренда имеет вид y = at + b.
1. Находим параметры уравнения методом наименьших квадратов
.
Система уравнений МНК:
a 0 n + a 1 ∑t = ∑y
a 0 ∑t + a 1 ∑t 2 = ∑y t
| t | y | t 2 | y 2 | t y | y(t) | (y-y cp) 2 | (y-y(t)) 2 | (t-t p) 2 | (y-y(t)) : y |
| 1 | 17.4 | 1 | 302.76 | 17.4 | 12.26 | 895.01 | 26.47 | 30.25 | 0.3 |
| 2 | 26.9 | 4 | 723.61 | 53.8 | 18.63 | 416.84 | 68.39 | 20.25 | 0.31 |
| 3 | 23 | 9 | 529 | 69 | 25 | 591.3 | 4.02 | 12.25 | 0.0872 |
| 4 | 23.7 | 16 | 561.69 | 94.8 | 31.38 | 557.75 | 58.98 | 6.25 | 0.32 |
| 5 | 27.2 | 25 | 739.84 | 136 | 37.75 | 404.68 | 111.4 | 2.25 | 0.39 |
| 6 | 34.5 | 36 | 1190.25 | 207 | 44.13 | 164.27 | 92.72 | 0.25 | 0.28 |
| 7 | 50.7 | 49 | 2570.49 | 354.9 | 50.5 | 11.45 | 0.0383 | 0.25 | 0.0039 |
| 8 | 61.4 | 64 | 3769.96 | 491.2 | 56.88 | 198.34 | 20.44 | 2.25 | 0.0736 |
| 9 | 69.3 | 81 | 4802.49 | 623.7 | 63.25 | 483.27 | 36.56 | 6.25 | 0.0872 |
| 10 | 94.4 | 100 | 8911.36 | 944 | 69.63 | 2216.84 | 613.62 | 12.25 | 0.26 |
| 11 | 61.1 | 121 | 3733.21 | 672.1 | 76 | 189.98 | 222.11 | 20.25 | 0.24 |
| 12 | 78.2 | 144 | 6115.24 | 938.4 | 82.38 | 953.78 | 17.46 | 30.25 | 0.0534 |
| 78 | 567.8 | 650 | 33949.9 | 4602.3 | 567.8 | 7083.5 | 1272.21 | 143 | 2.41 |
Для наших данных система уравнений имеет вид:
12a 0 + 78a 1 = 567.8
78a 0 + 650a 1 = 4602.3
Из первого уравнения выражаем а 0 и подставим во второе уравнение
Получаем a 0 = 6.37, a 1 = 5.88
Примечание: значения столбца №6 y(t) рассчитываются на основе полученного уравнения тренда. Например, t = 1: y(1) = 6.37*1 + 5.88 = 12.26
Уравнение тренда
y = 6.37 t + 5.88Оценим качество уравнения тренда с помощью ошибки абсолютной аппроксимации.
![]()
Поскольку ошибка больше 15%, то данное уравнение не желательно использовать в качестве тренда.
Средние значения:
![]()
![]()
![]()
Дисперсия
![]()
Среднеквадратическое отклонение
Коэффициент эластичности
![]()
Коэффициент эластичности меньше 1. Следовательно, при изменении Х на 1%, Y изменится менее чем на 1%. Другими словами - влияние Х на Y не существенно.
Коэффициент детерминации

т.е. в 82.04 % случаев влияет на изменение данных. Другими словами - точность подбора уравнения тренда - высокая
2. Анализ точности определения оценок параметров уравнения тренда
.
Дисперсия ошибки уравнения.
где m = 1 - количество влияющих факторов в модели тренда.
Стандартная ошибка уравнения.
3. Проверка гипотез относительно коэффициентов линейного уравнения тренда
.
1) t-статистика. Критерий Стьюдента.
По таблице Стьюдента находим Tтабл
T табл (n-m-1;α/2) = (10;0.025) = 2.228
>
Статистическая значимость коэффициента a 0 подтверждается. Оценка параметра a 0 является значимой и тренд у временного ряда существует..
Статистическая значимость коэффициента a 1 не подтверждается.
Доверительный интервал для коэффициентов уравнения тренда
.
Определим доверительные интервалы коэффициентов тренда, которые с надежность 95% будут следующими:
(a 1 - t набл S a 1 ;a 1 + t набл S a 1)
(6.375 - 2.228*0.943; 6.375 + 2.228*0.943)
(4.27;8.48)
(a 0 - t набл S a 0 ;a 0 + t набл S a 0)
(5.88 - 2.228*6.942; 5.88 + 2.228*6.942)
(-9.59;21.35)
Так как точка 0 (ноль) лежит внутри доверительного интервала, то интервальная оценка коэффициента a 0 статистически незначима.
2) F-статистика. Критерий Фишера.

Fkp = 4.84
Поскольку F > Fkp, то коэффициент детерминации статистически значим
Проверка на наличие автокорреляции остатков
.
Важной предпосылкой построения качественной регрессионной модели по МНК является независимость значений случайных отклонений от значений отклонений во всех других наблюдениях. Это гарантирует отсутствие коррелированности между любыми отклонениями и, в частности, между соседними отклонениями.
Автокорреляция (последовательная корреляция)
определяется как корреляция между наблюдаемыми показателями, упорядоченными во времени (временные ряды) или в пространстве (перекрестные ряды). Автокорреляция остатков (отклонений) обычно встречается в регрессионном анализе при использовании данных временных рядов и очень редко при использовании перекрестных данных.
В экономических задачах значительно чаще встречается положительная автокорреляция
, нежели отрицательная автокорреляция
. В большинстве случаев положительная автокорреляция вызывается направленным постоянным воздействием некоторых неучтенных в модели факторов.
Отрицательная автокорреляция
фактически означает, что за положительным отклонением следует отрицательное и наоборот. Такая ситуация может иметь место, если ту же зависимость между спросом на прохладительные напитки и доходами рассматривать по сезонным данным (зима-лето).
Среди основных причин, вызывающих автокорреляцию
, можно выделить следующие:
1. Ошибки спецификации. Неучет в модели какой-либо важной объясняющей переменной либо неправильный выбор формы зависимости обычно приводят к системным отклонениям точек наблюдения от линии регрессии, что может обусловить автокорреляцию.
2. Инерция. Многие экономические показатели (инфляция, безработица, ВНП и т.д.) обладают определенной цикличностью, связанной с волнообразностью деловой активности. Поэтому изменение показателей происходит не мгновенно, а обладает определенной инертностью.
3. Эффект паутины. Во многих производственных и других сферах экономические показатели реагируют на изменение экономических условий с запаздыванием (временным лагом).
4. Сглаживание данных. Зачастую данные по некоторому продолжительному временному периоду получают усреднением данных по составляющим его интервалам. Это может привести к определенному сглаживанию колебаний, которые имелись внутри рассматриваемого периода, что в свою очередь может служить причиной автокорреляции.
Последствия автокорреляции схожи с последствиями гетероскедастичности
: выводы по t- и F-статистикам, определяющие значимость коэффициента регрессии и коэффициента детерминации, возможно, будут неверными.
Обнаружение автокорреляции
1. Графический метод
Есть ряд вариантов графического определения автокорреляции. Один из них увязывает отклонения e i с моментами их получения i. При этом по оси абсцисс откладывают либо время получения статистических данных, либо порядковый номер наблюдения, а по оси ординат – отклонения e i (либо оценки отклонений).
Естественно предположить, что если имеется определенная связь между отклонениями, то автокорреляция имеет место. Отсутствие зависимости скорее всего будет свидетельствовать об отсутствии автокорреляции.
Автокорреляция становится более наглядной, если построить график зависимости e i от e i-1
Критерий Дарбина-Уотсона
.
Этот критерий является наиболее известным для обнаружения автокорреляции.
При статистическом анализе уравнения регрессии на начальном этапе часто проверяют выполнимость одной предпосылки: условия статистической независимости отклонений между собой. При этом проверяется некоррелированность соседних величин e i .
| y | y(x) | e i = y-y(x) | e 2 | (e i - e i-1) 2 |
| 17.4 | 12.26 | 5.14 | 26.47 | 0 |
| 26.9 | 18.63 | 8.27 | 68.39 | 9.77 |
| 23 | 25 | -2 | 4.02 | 105.57 |
| 23.7 | 31.38 | -7.68 | 58.98 | 32.2 |
| 27.2 | 37.75 | -10.55 | 111.4 | 8.26 |
| 34.5 | 44.13 | -9.63 | 92.72 | 0.86 |
| 50.7 | 50.5 | 0.2 | 0.0384 | 96.53 |
| 61.4 | 56.88 | 4.52 | 20.44 | 18.71 |
| 69.3 | 63.25 | 6.05 | 36.56 | 2.33 |
| 94.4 | 69.63 | 24.77 | 613.62 | 350.63 |
| 61.1 | 76 | -14.9 | 222.11 | 1574.09 |
| 78.2 | 82.38 | -4.18 | 17.46 | 115.03 |
| 1272.21 | 2313.98 |
Для анализа коррелированности отклонений используют статистику Дарбина-Уотсона
:
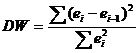
![]()
Критические значения d 1 и d 2 определяются на основе специальных таблиц для требуемого уровня значимости α, числа наблюдений n = 12 и количества объясняющих переменных m=1.
Автокорреляция отсутствует, если выполняется следующее условие:
d 1 < DW и d 2 < DW < 4 - d 2 .
Не обращаясь к таблицам, можно пользоваться приблизительным правилом и считать, что автокорреляция остатков отсутствует, если 1.5 < DW < 2.5. Поскольку 1.5 < 1.82 < 2.5, то автокорреляция остатков отсутствует
.
Для более надежного вывода целесообразно обращаться к табличным значениям.
По таблице Дарбина-Уотсона для n=12 и k=1 (уровень значимости 5%) находим: d 1 = 1.08; d 2 = 1.36.
Поскольку 1.08 < 1.82 и 1.36 < 1.82 < 4 - 1.36, то автокорреляция остатков отсутствует
.
Проверка наличия гетероскедастичности
.
1) Методом графического анализа остатков
.
В этом случае по оси абсцисс откладываются значения объясняющей переменной X, а по оси ординат либо отклонения e i , либо их квадраты e 2 i .
Если имеется определенная связь между отклонениями, то гетероскедастичность имеет место. Отсутствие зависимости скорее всего будет свидетельствовать об отсутствии гетероскедастичности.
2) При помощи теста ранговой корреляции Спирмена
.
Коэффициент ранговой корреляции Спирмена
.
Присвоим ранги признаку Y и фактору X. Найдем сумму разности квадратов d 2 .
По формуле вычислим коэффициент ранговой корреляции Спирмена.
![]()
| t | e i | ранг X, d x | ранг e i , d y | (d x - d y) 2 |
| 1 | -5.14 | 1 | 4 | 9 |
| 2 | -8.27 | 2 | 2 | 0 |
| 3 | 2 | 3 | 7 | 16 |
| 4 | 7.68 | 4 | 9 | 25 |
| 5 | 10.55 | 5 | 11 | 36 |
| 6 | 9.63 | 6 | 10 | 16 |
| 7 | -0.2 | 7 | 6 | 1 |
| 8 | -4.52 | 8 | 5 | 9 | t табл (n-m-1;α/2) = (10;0.05/2) = 2.228
Ряда. Уравнение тренда.
Кривые роста, описывающие закономерности развития явлений во времени, - это результат аналитического выравнивания динамических рядов. Выравнивание ряда с помощью тех или иных функций (т. е. их подгонка к данным) в большинстве случаев оказывается удобным средством описания эмпирических данных. Это средство при соблюдении ряда условий можно применить и для прогнозирования. Процесс выравнивания состоит из следующих основных этапов:
Выбора типа кривой, форма которой соответствует характеру изменения динамического ряда;
Определения численных значений (оценивание) параметров кривой;
Апостериорного контроля качества выбранного тренда.
В современных ППП все перечисленные этапы реализуются одновременно, как правило, в рамках одной процедуры.
Аналитическое сглаживание с использованием той или иной функции позволяет получить выравненные, или, как их иногда не вполне правомерно называют, теоретические значения уровней динамического ряда, т. е. те уровни, которые наблюдались бы, если бы динамика явления полностью совпадала с кривой. Эта же функция с некоторой корректировкой или без нее, применяется в качестве модели для экстраполяции (прогноза).
Вопрос о выборе типа кривой является основным при выравнивании ряда. При всех прочих равных условиях ошибка в решении этого вопроса оказывается более значимой по своим последствиям (особенно для прогнозирования), чем ошибка, связанная со статистическим оцениванием параметров.
Поскольку форма тренда объективно существует, то при выявлении ее следует исходить из материальной природы изучаемого явления, исследуя внутренние причины его развития, а также внешние условия и факторы на него влияющие. Только после глубокого содержательного анализа можно переходить к использованию специальных приемов, разработанных статистикой.
Весьма распространенным приемом выявления формы тренда является графическое изображение временного ряда. Но при этом велико влияние субъективного фактора, даже при отображении выровненных уровней.
Наиболее надежные методы выбора уравнения тренда основаны на свойствах различных кривых, применяемых при аналитическом выравнивании. Такой подход позволяет увязать тип тренда с теми или иными качественными свойствами развития явления. Нам представляется, что в большинстве случаев практически приемлемым является метод, который основывается на сравнении характеристик изменения приростов исследуемого динамического ряда с соответствующими характеристиками кривых роста. Для выравнивания выбирается та кривая, закон изменения прироста которой наиболее близок к закономерности изменения фактических данных.
В табл. 4 приводится перечень наиболее употребительных при анализе экономических рядов видов кривых и указываются соответствующие «симптомы», по которым можно определить, какой вид кривых подходит для выравнивания.
При выборе формы кривой надо иметь в виду еще одно обстоятельство. Рост сложности кривой в целом ряде случаев может действительно увеличить точность описания тренда в прошлом, однако в связи с тем, что более сложные кривые содержат большее число параметров и более высокие степени независимой переменной, их доверительные интервалы будут в общем существенно шире, чем у более простых кривых при одном и том же периоде упреждения.
Таблица 4
Характер изменения показателей, основанных
на средних приростах для различных видов кривых
| Показатель | Характер изменения показателей во времени | Вид кривой |
| Примерно одинаковые | Прямая | |
| Линейно изменяются | Парабола второй степени | |
| Линейно изменяются | Парабола третьей степени | |
| Примерно одинаковые | Экспонента | |
| Линейно изменяются | Логарифмическая парабола | |
| Линейно изменяются | Модифицированная экспонента | |
| Линейно изменяются | Кривая Гомперца |
В настоящее время, когда использование специальных программ без особых усилий позволяет одновременно строить несколько видов уравнений, широко эксплуатируются формальные статистические критерии для определения лучшего уравнения тренда.
Из сказанного выше, по-видимому, можно сделать вывод о том, что выбор формы кривой для выравнивания представляет собой задачу, которая не решается однозначно, а сводится к получению ряда альтернатив. Окончательный выбор не может лежать в области формального анализа, тем более, если предполагается с помощью выравнивания не только статистически описать закономерность поведения уровня в прошлом, но и экстраполировать найденную закономерность в будущее. Вместе с тем различные статистические приемы обработки данных наблюдения могут принести существенную пользу, по крайней мере, с их помощью можно отвергнуть заведомо непригодные варианты и тем самым существенно ограничить поле выбора.
Рассмотрим наиболее используемые типы уравнений тренда:
1.Линейная форма тренда:
где - уровень ряда, полученный в результате выравнивания по прямой;
Начальный уровень тренда;
Средний абсолютный прирост; константа тренда.
Для линейной формы тренда характерно равенство так называемых первых разностей (абсолютных приростов) и нулевые вторые разности, т. е. ускорения.
2.Параболическая (полином 2-ой степени) форма тренда:
![]()
Для данного типа кривой постоянными являются вторые разности (ускорение), а нулевыми – третьи разности.
Параболическая форма тренда соответствует ускоренному или замедленному изменению уровней ряда с постоянным ускорением. Если < 0 и > 0, то квадратическая парабола имеет максимум, если > 0 и < 0 – минимум. Для отыскания экстремума первую производную параболы по t приравнивают 0 и решают уравнение относительно t.
3.Экспоненциальная форма тренда:
где - константа тренда; средний темп изменения уровня ряда.
При > 1 данный тренд может отражать тенденцию ускоренного и все более ускоряющегося возрастания уровней ряда. При < 1 – тенденцию постоянно, все более замедляющегося снижения уровней временного ряда.
4.Гиперболическая форма тренда (1 типа):
Данная форма тренда может отображать тенденцию процессов, ограниченных предельным значением уровня.
5.Логарифмическая форма тренда:
где - константа тренда.
Логарифмическим трендом может быть описана тенденция, проявляющаяся в замедлении роста уровней ряда динамики при отсутствии предельно возможного значения. При достаточно большом t логарифмическая кривая становится мало отличимой от прямой линии.
6.Обратнологарифмическая форма тренда:
![]()
7.Мультипликативная (степенная) форма тренда:
8.Обратная (гиперболическая 2 типа) форма тренда:
9.Гиперболическая форма тренда 3 типа:
10.Полином 3-ей степени:
![]()
Для всех нелинейных, относительно исходных переменных моделей (уравнений регрессии), а их здесь большинство, требуется провести вспомогательные преобразования, представленные в таблице ниже.
Таблица 5
Модели, сводящиеся к линейному тренду
| Модель | Уравнение | Преобразование |
| Мультипликативная (Степенная) | ||
| Гиперболическая I типа | ||
| Гиперболическая II типа | ||
| Гиперболическая III типа | ||
| Логарифмическая | ||
| Обратнологарифмическая |
В формулах, перечисленных в таблице, как и во всех формулах, описывающих модель тренда, есть коэффициенты уравнений.
Однако, при практическом использовании линеаризации с помощью преобразования исследуемых переменных следует иметь ввиду, что оценки параметров, полученных линеаризацией с помощью М.Н.К. (метод наименьших квадратов), минимизируют сумму квадратов отклонений для преобразованных, а не исходных переменных. Поэтому полученные с помощью линеаризации зависимостей оценки нуждаются в уточнении.
Для решения поставленной задачи по аналитическому сглаживанию динамических рядов в системе STATISTICA нам потребуется создать несколько новых дополнительных переменных, необходимых для выполнения дальнейшей работы, а также осуществить некоторые вспомогательные операции по преобразованию нелинейных моделей тренда в линейные.
Итак, нам предстоит построить уравнение тренда, которое по существу является уравнением регрессии, в котором в качестве фактора выступает «время». Прежде всего, мы создадим переменную «Т», содержащую моменты времени четвертого периода. Так как четвертый период включает 12 лет, то переменная «Т» будет состоять из натуральных чисел от 1 до 12, соответствующих месяцам года.
Кроме того, для работы с некоторыми моделями тренда нам потребуется еще несколько переменных, содержание которых можно понять из их обозначения. Это переменные, получаемые из временного ряда: «Т^2», «Т^3», «1/Т» и «ln T». А также переменные, получаемые из исходных данных за четвертый период: «1/Import4» и «ln Import4». Также необходимо создать такую же таблицу для экспорта. Все это предлагается сделать на новом рабочем листе, скопировав туда данные за 4-й период.
Для этого воспользуемся уже известным нам меню Workbook/Insert.
В итоге получаем следующие электронные таблицы.

Рис. 38. Таблица со вспомогательными переменными для импорта

Рис. 39. Таблица со вспомогательными переменными для экспорта
Для аналитического выравнивания рядов динамики мы будем использовать модуль Multiple Regression в меню Statistics. Рассмотрим пример построения графического изображения и определение численных параметров тренда, выраженного линейной зависимостью.

Рис. 40. Модуль Multiple Regression в меню Statistics
Для выбора зависимых и независимых переменных воспользуемся кнопкой Variables.
В открывшемся окне в левом информационном поле мы выбираем зависимую переменную Y t , (в нашем случае это Import 4 – данные по четвертому периоду). Номера выбранных зависимых переменных отображаются внизу в поле Dependent var. (or list for batch). Соответственно в правом поле мы выбираем независимые переменные (в нашем случае одну – время «Т»). Номера выбранных независимых переменных высвечиваются внизу в поле Independent variable list.
После того, как завершен выбор переменных, нажимаем ОК. Система выдает окно с обобщенными результатами расчета параметров тренда (далее они будут рассмотрены более подробно) и возможностью выбора направления для последующего детального анализа. Заметим, что значение оценки, высвеченное красным цветом, указывает на статистическую значимость результатов.

Рис. 41. Закладка Advanced
На закладке располагается несколько кнопок, позволяющих получить максимально детализированные сведения по интересующему нас направлению анализа. При нажатии на нее получаем две таблицы с результатами регрессионного анализа. В первой представлены результаты расчета параметров уравнения регрессии, во второй – основные показатели уравнения.

Рис. 42. Основные показатели уравнения для данных импорта за четвертый период (линейный тренд)
Здесь N = – объем результативной переменной. В верхнем поле расположены показатели R, , Adjusted R, F, p, Std.Error of Estimate , означающие соответственно теоретическое корреляционное отношение, коэффициент детерминации, уточненный коэффициент детерминации, расчетное значение критерия Фишера (в скобках дано число степеней свободы), уровень значимости, стандартная ошибка уравнения (эти же показатели можно увидеть во второй таблице). В самой таблице нас интересуют столбец В , в котором расположены коэффициенты уравнения, столбец t и столбец p-level , обозначающие расчетное значение t-критерия и расчетный уровень значимости, необходимые для оценки значимости параметров уравнения. При этом система помогает пользователю: когда процедура предполагает проверку на значимость, STATISTICA выделяет значимые элементы красным цветом (т.е. отвергается нулевая гипотеза о равенстве параметров нулю). В нашем случае |t факт | > t табл для обоих параметров, следовательно они значимы.

Рис. 43. Параметры уравнения регрессии для данных импорта за четвертый период (линейный тренд)
Для оценки статистической значимости уравнения в целом на закладке Advanced воспользуемся кнопкой ANOVA (Goodness Of Fit), позволяющей получить таблицу дисперсионного анализа и значение F-критерия Фишера.

Рис. 44. Таблица дисперсионного анализа
Sums of Squares – сумма квадратов отклонений: на пересечении со строкой Regression – сумма квадратов отклонений теоретических (полученных по уравнению регрессии) значений признака от средней величины. Эта сумма квадратов используется для расчета факторной, объясненной дисперсии зависимой переменной. На пересечении со строкой Residual – сумма квадратов отклонений теоретических и фактических значений переменной (для расчета остаточной, необъясненной дисперсии), Total – отклонений фактических значений переменной от средней величины (для расчета общей дисперсии). Столбец df – число степеней свободы, Means Squares обозначает дисперсию: на пересечении со строкой Regression – факторную, со строкой Residual - остаточную, F – критерий Фишера, используемый для оценки общей значимости уравнения и коэффициента детерминации, p-level – уровень значимости.
Параметры уравнения тренда в STATISTICA, как и в большинстве других программ, рассчитываются по метод наименьших квадратов (МНК).
Метод позволяет получить значения параметров, при которых обеспечивается минимизация суммы квадратов отклонений фактических уровней от сглаженных, т. е. полученных в результате аналитического выравнивания.
Математический аппарат метода наименьших квадратов описан в большинстве работ по математической статистике, поэтому нет необходимости подробно на нем останавливаться. Напомним только некоторые моменты. Так, для нахождения параметров линейного тренда (2.10) необходимо решить систему уравнений:

Данная система уравнений упрощается, если значения t подобрать таким образом, чтобы их сумма равнялась нулю, т. е. начало отсчета времени перенести в середину рассматриваемого периода. Очевидно, что перенос начала координат имеет смысл только при ручной обработке динамического ряда.
Если , то , .
В общем виде систему уравнений для нахождения параметров полинома ![]() можно записать как
можно записать как

При сглаживании временного ряда по экспоненте (которая часто используется в экономических исследованиях) для определения параметров следует применить метод наименьших квадратов к логарифмам исходных данных.
![]()
После переноса начала отсчета времени в середину ряда получают:
![]()
следовательно:

Если наблюдаются более сложные изменения уровней временного ряда и выравнивание осуществляется по показательной функции вида , то параметры определяются в результате решения следующей системы уравнений:

В практике исследования социально-экономических явлений исключительно редко встречаются динамические ряды, характеристики которых полностью соответствуют признакам эталонных математических функций. Это обусловлено значительным числом факторов разного характера, влияющих на уровни ряда и тенденцию их изменения.
На практике чаще всего строят целый ряд функций, описывающих тренд, а затем выбирают лучшую на основе того или иного формального критерия.

Рис. 45. Закладка Residuals/Assumptions/Prediction
Здесь воспользуемся кнопкой Perform Residual Analysis, открывающую модуль анализа остатков. Под остатками (Residuals) в данном случае понимается отклонение исходных значений динамического ряда от прогнозируемых, в соответствии с выбранным уравнением тренда. Сразу же переходим к закладке Advanced.

Рис. 46. Закладка Advanced в Perform Residual Analysis
Воспользуемся кнопкой Summary: Residuals & Predicted, позволяющую получить одноименную таблицу, которая содержит исходные значения динамического ряда Observed Value, прогнозируемые значения по выбранной модели тренда Predicted Value, отклонения прогнозных значений от исходных Residual Value, а также различные специальные показатели и стандартизированные значения. Также в таблице представлены максимальное, минимальное значения, средняя и медиана по каждому столбцу.

Рис. 47. Таблица, содержащая показатели и специальные значения для линейного тренда
В данной таблицы наибольший интерес для нас представляет столбец Residual Value, значения которого в дальнейшем используются для характеристики качества подбора тренда, а также столбец Predicted Value, который содержит прогнозные значения динамического ряда в соответствии с выбранной моделью тренда (в нашем случае – линейной).
Далее построим график исходного временного ряда совместно с вычисленными в соответствии с линейным уравнением тренда прогнозными значениями для четвертого периода. Для этого лучше всего скопировать значения из столбца Predicted Value в таблицу, в которой были созданы переменные для построения трендов.

Рис. 48. Третий период динамического ряда импорта (млрд. $) и линейный тренд
Итак, мы получили все необходимые результаты расчета параметров тренда, выраженного линейной моделью, для четвертого периода исходного динамического ряда, а также построили график данного ряда, совмещенный с линией тренда. Далее будут представлены остальные модели трендов.
Следует заметить, что в результате линеаризации степенной и экспоненциальной функций STATISTICA возвращает значение линеаризованной функции равное , поэтому для дальнейшего использования их надо преобразовать с помощью следующей элементарной транзакции , в том числе и для построения графических изображений. Для гиперболических функций, а также для обратнологарифмической функции необходимо выполнить преобразование вида .
Для этого также целесообразно создать дополнительные переменные и получить их с помощью формул на основе уже имеющихся переменных.
Итак, при решении задачи с помощью процедуры Multiple Regression, необходимо в качестве переменных выбрать натуральные логарифмы исходного ряда и оси времени.

Рис. 49. Основные показатели уравнения для данных импорта за третий период (степенная модель)

Рис. 50. Параметры уравнения регрессии для данных импорта за третий период (степенная модель)

Рис. 51. Таблица дисперсионного анализа

Рис. 52. Таблица, содержащая показатели и специальные значения для степенной модели
Затем, как и в случае с линейным трендом, копируем значения из столбца Predicted Value в таблицу, но там для этого строим еще одну переменную, в которой получаем прогнозные значения по степенной функции с помощью преобразования .

Рис. 53. Создание дополнительной переменной

Рис. 54. Таблица со всеми переменными

Рис. 55. Третий период динамического ряда импорта (млрд. $) и степенная модель

Рис.56. Основные показатели уравнения для данных импорта за третий период (экспоненциальная модель)

Рис. 57. Третий период динамического ряда импорта (млрд. $) и экспоненциальная модель

Рис.58. Основные показатели уравнения для данных импорта за третий период (обратная модель)

Рис. 59. Третий период динамического ряда импорта (млрд. $) и обратная модель

Рис. 60. Основные показатели уравнения для данных импорта за третий период (полином второй степени)

Рис. 61. Третий период динамического ряда импорта (млрд. $) и полином второй степени

Рис. 62. Основные показатели уравнения для данных импорта за третий период (полином 3-й степени)

Рис. 63. Третий период динамического ряда импорт (млрд. $) и полином 3-й степени

Рис. 64. Основные показатели уравнения для данных импорта за третий период (гипербола 1-ого вида)

Рис. 65. Третий период динамического ряда импорт (млрд. $) и гипербола 1-ого вида

Рис. 66. Основные показатели уравнения для данных импорта за третий период (гипербола 3 типа)

Рис. 67. Третий период динамического ряда импорт и гипербола 3 типа

Рис. 68. Основные показатели уравнения для данных импорта за третий период (логарифмическая модель)

Рис. 69. Третий период динамического ряда импорт (млрд. $) и логарифмическая модель

Рис. 70. Основные показатели уравнения для данных импорта за третий период (обратнологарифмическая модель)

Рис. 71. Третий период динамического ряда импорт (млрд. $) и обратнологарифмическая модель
Затем построим таблицу со вспомогательными переменными для построения трендов для экспорта.

Рис. 72. Таблица со вспомогательными переменными
Проделаем те же операции что и для четвертого период импорта.

Рис. 73. Основные показатели уравнения для данных экспорта за третий период (линейная модель)

Рис. 74. Третий период динамического ряда экспорта (млрд. $) и линейная модель

Рис. 75. Основные показатели уравнения для данных экспорта за третий период (степенная модель тренда)

Рис. 76. Третий период динамического ряда экспорта и степенная модель

Рис. 77. Основные показатели уравнения для данных экспорта за третий период (экспоненциальная модель тренда)

Рис. 78. Третий период динамического ряда экспорта (млрд. $) и экспоненциальная модель

Рис. 79. Основные показатели уравнения для данных экспорта за третий период (обратная модель тренда)
 Рис. 80. Третий период динамического ряда экспорта (млрд. $) и обратная модель
Рис. 80. Третий период динамического ряда экспорта (млрд. $) и обратная модель

Рис. 81. Основные показатели уравнения для данных экспорта за третий период (полином второй степени)

Рис. 82. Третий период динамического ряда экспорта (млрд. $) и полином второй степени

Рис. 83. Основные показатели уравнения для данных экспорта за третий период (полином третей степени)

Рис. 84. Третий период динамического ряда экспорта (млрд. $) и полином третей степени

Рис. 85. Основные показатели уравнения для данных экспорта за третий период (гипербола 1-ого вида)

Рис. 86. Третий период динамического ряда экспорта и гипербола 1-ого типа

Рис. 87. Основные показатели уравнения для данных экспорта за третий период (гипербола 3-ого вида)

Рис. 88. Третий период динамического ряда экспорта (млрд. $) и гипербола 3-ого типа

Рис. 89. Основные показатели уравнения для данных экспорта за третий период (логарифмическая модель)

Рис. 90. Третий период динамического ряда экспорта (млрд. $) и логарифмическая модель

Рис. 91. Основные показатели уравнения для данных экспорта за третий период (обратнологарифмическая модель)

Рис. 91. Третий период динамического ряда экспорта (млрд. $) и обратнологарифмическая модель
Выбор наилучшего тренда
Как уже отмечалось, проблема выбора формы кривой - одна из основных проблем, с которой сталкиваются при выравнивании ряда динамики. Решение этой проблемы во многом определяет результаты экстраполяции тренда. В большинстве специализированных программ для выбора лучшего уравнения тренда предоставляется возможность воспользоваться следующими критериями:
Минимальное значение среднеквадратической ошибки тренда:
 ,
,
где - фактические уровни ряда динамики;
Уровни ряда, определенные по уравнению тренда;
n - число уровней ряда;
p - число факторовв уравнении тренда.
- минимальное значение остаточной дисперсии:
![]()
Минимальное значение средней ошибки аппроксимации;
Минимальное значение средней абсолютной ошибки;
Максимальное значение коэффициента детерминации;
Максимальное значение F- критерия Фишера:
 : ,
: ,
где k – число степеней свободы факторной дисперсии,равное числу независимых переменных (признаков-факторов) в уравнении;
n-k-1 - число степеней свободы остаточной дисперсии.
Применение формального критерия для выбора формы кривой, по-видимому, даст практически пригодные результаты в том случае, если отбор будет проходить в два этапа. На первом этапе отбираются зависимости, пригодные с позиции содержательного подхода к задаче, в результате чего происходит ограничение круга потенциально приемлемых функций. На втором этапе для этих функций подсчитываются значения критерия и выбирается та из кривых, которой соответствует минимальное его значение.
В данном пособии для идентификации тренда используется формальный метод, который основывается на использовании численного критерия. В качестве такого критерия рассматривается максимальный коэффициент детерминации:
 .
.
Расшифровка обозначений и формулы данных показателей даны в предыдущих разделах. Коэффициент детерминации показывает, какая доля общей дисперсии результативного признака обусловлена вариацией признака – фактора. В таблицах STATISTICA он обозначается как R?.
В следующей ниже таблице будут представлены уравнения моделей трендов и коэффициенты детерминации данных импорта.
Таблица 6
Уравнения моделей трендов и коэффициенты детерминации Import.
Сопоставив значения коэффициентов детерминации для различных типов кривых можно сделать вывод о том, что для исследуемого третьего периода лучшей формой тренда будет полином третей степени для импорта и для экспорта.
Далее необходимо проанализировать выбранную модель тренда с точки зрения ее адекватности реальным тенденциям исследуемого временного ряда через оценку надежности полученных уравнений трендов по F-критерию Фишера. В данном случае расчетное значение критерия Фишера для импорта равно 16,573; для экспорта – 13,098, а табличное значение при уровне значимости равно 3,07. Следовательно, эта модель тренда признается адекватно отражающей реальную тенденцию изучаемого явления.
Для наглядной иллюстрации тенденций изменения цены применяется линия тренда. Элемент технического анализа представляет собой геометрическое изображение средних значений анализируемого показателя.
Рассмотрим, как добавить линию тренда на график в Excel.
Добавление линии тренда на график
Для примера возьмем средние цены на нефть с 2000 года из открытых источников. Данные для анализа внесем в таблицу:


Линия тренда в Excel – это график аппроксимирующей функции. Для чего он нужен – для составления прогнозов на основе статистических данных. С этой целью необходимо продлить линию и определить ее значения.
Если R2 = 1, то ошибка аппроксимации равняется нулю. В нашем примере выбор линейной аппроксимации дал низкую достоверность и плохой результат. Прогноз будет неточным.
Внимание!!! Линию тренда нельзя добавить следующим типам графиков и диаграмм:
- лепестковый;
- круговой;
- поверхностный;
- кольцевой;
- объемный;
- с накоплением.
Уравнение линии тренда в Excel
В предложенном выше примере была выбрана линейная аппроксимация только для иллюстрации алгоритма. Как показала величина достоверности, выбор был не совсем удачным.
Следует выбирать тот тип отображения, который наиболее точно проиллюстрирует тенденцию изменений вводимых пользователем данных. Разберемся с вариантами.
Линейная аппроксимация
Ее геометрическое изображение – прямая. Следовательно, линейная аппроксимация применяется для иллюстрации показателя, который растет или уменьшается с постоянной скоростью.
Рассмотрим условное количество заключенных менеджером контрактов на протяжении 10 месяцев:

На основании данных в таблице Excel построим точечную диаграмму (она поможет проиллюстрировать линейный тип):

Выделяем диаграмму – «добавить линию тренда». В параметрах выбираем линейный тип. Добавляем величину достоверности аппроксимации и уравнение линии тренда в Excel (достаточно просто поставить галочки внизу окна «Параметры»).

Получаем результат:

Обратите внимание! При линейном типе аппроксимации точки данных расположены максимально близко к прямой. Данный вид использует следующее уравнение:
y = 4,503x + 6,1333
- где 4,503 – показатель наклона;
- 6,1333 – смещения;
- y – последовательность значений,
- х – номер периода.
Прямая линия на графике отображает стабильный рост качества работы менеджера. Величина достоверности аппроксимации равняется 0,9929, что указывает на хорошее совпадение расчетной прямой с исходными данными. Прогнозы должны получиться точными.
Чтобы спрогнозировать количество заключенных контрактов, например, в 11 периоде, нужно подставить в уравнение число 11 вместо х. В ходе расчетов узнаем, что в 11 периоде этот менеджер заключит 55-56 контрактов.
Экспоненциальная линия тренда
Данный тип будет полезен, если вводимые значения меняются с непрерывно возрастающей скоростью. Экспоненциальная аппроксимация не применяется при наличии нулевых или отрицательных характеристик.
Построим экспоненциальную линию тренда в Excel. Возьмем для примера условные значения полезного отпуска электроэнергии в регионе Х:

Строим график. Добавляем экспоненциальную линию.

Уравнение имеет следующий вид:
y = 7,6403е^-0,084x
- где 7,6403 и -0,084 – константы;
- е – основание натурального логарифма.
Показатель величины достоверности аппроксимации составил 0,938 – кривая соответствует данным, ошибка минимальна, прогнозы будут точными.
Логарифмическая линия тренда в Excel
Используется при следующих изменениях показателя: сначала быстрый рост или убывание, потом – относительная стабильность. Оптимизированная кривая хорошо адаптируется к подобному «поведению» величины. Логарифмический тренд подходит для прогнозирования продаж нового товара, который только вводится на рынок.
На начальном этапе задача производителя – увеличение клиентской базы. Когда у товара будет свой покупатель, его нужно удержать, обслужить.
Построим график и добавим логарифмическую линию тренда для прогноза продаж условного продукта:

R2 близок по значению к 1 (0,9633), что указывает на минимальную ошибку аппроксимации. Спрогнозируем объемы продаж в последующие периоды. Для этого нужно в уравнение вместо х подставлять номер периода.
Например:
| Период | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| Прогноз | 1005,4 | 1024,18 | 1041,74 | 1058,24 | 1073,8 | 1088,51 | 1102,47 |
Для расчета прогнозных цифр использовалась формула вида: =272,14*LN(B18)+287,21. Где В18 – номер периода.
Полиномиальная линия тренда в Excel
Данной кривой свойственны переменные возрастание и убывание. Для полиномов (многочленов) определяется степень (по количеству максимальных и минимальных величин). К примеру, один экстремум (минимум и максимум) – это вторая степень, два экстремума – третья степень, три – четвертая.
Полиномиальный тренд в Excel применяется для анализа большого набора данных о нестабильной величине. Посмотрим на примере первого набора значений (цены на нефть).

Чтобы получить такую величину достоверности аппроксимации (0,9256), пришлось поставить 6 степень.
Зато такой тренд позволяет составлять более-менее точные прогнозы.
Кривые роста, описывающие закономерности развития явлений во времени – это результат аналитического выравнивания динамических рядов. Выравнивание ряда с помощью тех или иных функций в большинстве случаев оказывается удобным средством описания эмпирических данных. Это средство при соблюдении ряда условий можно применить и для прогнозирования. Процесс выравнивания состоит из следующих основных этапов:
Выбора типа кривой, форма которой соответствует характеру изменения динамического ряда;
Определения численных значений (оценка) параметров кривой;
Апостериорного контроля качества выбранного тренда.
В современных ППП все перечисленные этапы реализуются одновременно, как правило, в рамках одной процедуры.
Аналитическое сглаживание с использованием той или иной функции позволяет получить выровненные, или, как их иногда не вполне правомерно называют, теоретические значения уровней динамического ряда, т. е. уровни, которые наблюдались бы, если бы динамика явления полностью совпадала с кривой. Эта же функция с некоторой корректировкой или без нее, применяется в качестве модели для экстраполяции (прогноза).
Вопрос о выборе типа кривой является основным при выравнивании ряда. При всех прочих равных условиях ошибка в решении этого вопроса оказывается более значимой по своим последствиям (особенно для прогнозирования), чем ошибка, связанная со статистическим оцениванием параметров.
Поскольку форма тренда объективно существует, то при выявлении ее следует исходить из материальной природы изучаемого явления, исследуя внутренние причины его развития, а также внешние условия и факторы на него влияющие. Только после глубокого содержательного анализа можно переходить к использованию специальных приемов, разработанных статистикой.
Весьма распространенным приемом выявления формы тренда является графическое изображение временного ряда. Но при этом велико влияние субъективного фактора, даже при отображении выровненных уровней.
Наиболее надежные методы выбора уравнения тренда основаны на свойствах различных кривых, применяемых при аналитическом выравнивании. Такой подход позволяет увязать тип тренда с теми или иными качественными свойствами развития явления. Нам представляется, что в большинстве случаев практически приемлемым является метод, который основывается на сравнении характеристик изменения приростов исследуемого динамического ряда с соответствующими характеристиками кривых роста. Для выравнивания выбирается та кривая, закон изменения прироста которой наиболее близок к закономерности изменения фактических данных.
При выборе формы кривой надо иметь в виду еще одно обстоятельство. Рост сложности кривой в целом ряде случаев может действительно увеличить точность описания тренда в прошлом, однако в связи с тем, что более сложные кривые содержат большее число параметров и более высокие степени независимой переменной, их доверительные интервалы будут, в общем, существенно шире, чем у более простых кривых при одном и том же периоде упреждения.
В настоящее время, когда использование специальных программ без особых усилий позволяет одновременно строить несколько видов уравнений, широко эксплуатируются формальные статистические критерии для определения лучшего уравнения тренда.
Из сказанного выше, по-видимому, можно сделать вывод о том, что выбор формы кривой для выравнивания представляет собой задачу, которая не решается однозначно, а сводится к получению ряда альтернатив. Окончательный выбор не может лежать в области формального анализа, тем более, если предполагается с помощью выравнивания не только статистически описать закономерность поведения уровня в прошлом, но и экстраполировать найденную закономерность в будущее. Вместе с тем различные статистические приемы обработки данных наблюдения могут принести существенную пользу, по крайней мере, с их помощью можно отвергнуть заведомо непригодные варианты и тем самым существенно ограничить поле выбора.
Рассмотрим наиболее используемые типы уравнений тренда:
1. Линейная форма тренда:
где – уровень ряда, полученный в результате выравнивания по прямой; – начальный уровень тренда; – средний абсолютный прирост, константа тренда.
Для линейной формы тренда характерно равенство так называемых первых разностей (абсолютных приростов) и нулевые вторые разности, т. е. ускорения.
2. Параболическая (полином 2-ой степени) форма тренда:
 (3.6)
(3.6)
Для данного типа кривой постоянными являются вторые разности (ускорение), а нулевыми – третьи разности.
Параболическая форма тренда соответствует ускоренному или замедленному изменению уровней ряда с постоянным ускорением. Если < 0 и > 0, то квадратическая парабола имеет максимум, если > 0 и < 0 – минимум. Для отыскания экстремума первую производную параболы по t приравнивают 0 и решают уравнение относительно t .
3. Логарифмическая форма тренда:
 , (3.7)
, (3.7)
где – константа тренда.
Логарифмическим трендом может быть описана тенденция, проявляющаяся в замедлении роста уровней ряда динамики при отсутствии предельно возможного значения. При достаточно большом t логарифмическая кривая становится мало отличимой от прямой линии.
4. Мультипликативная (степенная) форма тренда:
 (3.8)
(3.8)
5. Полином 3-ей степени:
Естественно, кривых, описывающих основные тенденции, гораздо больше. Однако формат учебного пособия не позволяет описать все их многообразие. Показанные далее приемы построения моделей позволят пользователю самостоятельно использовать другие функции, в частности обратные.
Для решения поставленной задачи по аналитическому сглаживанию динамических рядов в системе STATISTICA нам потребуется создать дополнительную переменную на листе с исходными данными переменной «ВГ2001-2010», который следует сделать активным.
Нам предстоит построить уравнение тренда, которое по существу является уравнением регрессии, в котором в качестве фактора выступает «время». Создаем переменную «Т», содержащую интервалы времени, 10 годам (с 2001 по 2010). Переменная «Т» будет состоять из натуральных чисел от 1 до 10, соответствующих указанным годам.
В итоге получается следующий рабочий лист (рис. 3.6)

Рис. 3.6. Рабочий лист с созданной переменной времени
Далее рассмотрим процедуру, позволяющую строить регрессионные модели как линейного, так и нелинейного типа. Для этого выбираем: Statistics/Advanced Linear/Nonlinear Models/Nonlinear Estimation (рис. 3.7). В появившемся окне (рис. 3.8) выбираем функцию User-specified Regression, Least Squares (построение моделей регрессии пользователем вручную, параметры уравнения находятся по методу наименьших квадратов (МНК)).
В следующем диалоговом окне (рис. 3.9) нажимаем на кнопку Function to be estimated , чтобы попасть на экран для задания модели вручную (рис. 3.10).

Рис. 3.7. Запуск процедуры Statistics/Advanced Linear/
Nonlinear Models/Nonlinear Estimation

Рис. 3.8. Окно процедуры Nonlinear Estimation

Рис. 3.9ю Окно процедуры User-Specified Regression, Least Squares

Рис. 3.10. Окно для реализации процедуры
задания уравнения тренда вручную
В верхней части экрана находится поле для ввода функции, в нижней части располагаются примеры ввода функций для различных ситуаций.
Прежде чем сформировать интересующие нас модели, необходимо пояснить некоторые условные обозначения. Переменные уравнений задаются в формате «v №», где «v » обозначает переменную (от англ. «variable »), а «№» – номер столбца, в котором она расположена в таблице на рабочем листе с исходными данными. Если переменных очень много, то справа находится кнопка Review vars , позволяющая выбирать их из списка по названиям и просматривать их параметры с помощью кнопки Zoom (рис. 3.11).

Рис. 3.11. Окно выбора переменной с помощью кнопки Review vars
Параметры уравнений обозначаются любыми латинскими буквами, не обозначающими какое-либо математическое действие. Для упрощения работы предлагается обозначать параметры уравнения так, как в описании уравнений тренда – латинской буквой «а », последовательно присваивая им порядковые номера. Знаки математических действий (вычитания, сложения, умножения и пр.) задаются в обычном для Windows -приложений формате. Пробелы между элементами уравнения не требуются.
Итак, рассмотрим первую модель тренда – линейную, .
Следовательно, после набора она будет выглядеть следующим образом:
![]() ,
,
где v 1 – это столбец на листе с исходными данными, в котором находятся значения исходного динамического ряда; а 0 и а 1 – параметры уравнения; v 2 – столбец на листе с исходными данными, в котором находятся значения интервалов времени (переменная Т) (рис. 3.12).
После этого дважды нажимаем кнопку ОК .

Рис. 3.12. Окно процедуры задания уравнения линейного тренда

Рис. 3.13. Закладка Quick процедуры оценки уравнения тренда.
В появившемся окне (рис. 3.13) можно выбрать метод оценки параметров уравнения регрессии (Estimation method ), если это необходимо. В нашем случае нужно перейти к закладке Advanced и нажать на кнопку Start values (рис. 3.14). В этом диалоге задаются стартовые значения параметров уравнения для их нахождения по МНК, т.е. их минимальные значения. Изначально они заданы как 0,1 для всех параметров. В нашем случае можно оставить эти значения в том же виде, но если значения в наших исходных данных меньше единицы, то необходимо задать их в виде 0,001 для всех параметров уравнения тренда (рис. 3.15). Далее нажимаем кнопку ОК .

Рис. 3.14. Закладка Advanced процедуры оценки уравнения тренда

Рис. 3.15. Окно задания стартовыхзначений параметров уравнения тренда

Рис. 3.16. Закладка Quick окна результатов регрессионного анализа
На закладке Quick (рис.3.16) очень важным является значение строчки Proportion of variance accounted for , которое соответствует коэффициенту детерминации; это значение лучше записать отдельно, так как в дальнейшем оно выводиться не будет, и пользователю придется рассчитывать коэффициент вручную, при этом достаточно трех знаков после запятой. Далее нажимаем кнопку Summary: Parameter estimates для получения данных о параметрах линейного уравнения тренда (рис. 3.17).

Рис. 3.17. Результаты расчета параметров линейной модели тренда
Столбец Estimate – числовые значения параметров уравнения; Standard еrror – стандартная ошибка параметра; t-value – расчетное значение t -критерия; df – число степеней свободы (n -2); p-level – расчетный уровень значимости; Lo. Conf. Limit и Up. Conf. Limit – соответственно нижняя и верхняя граница доверительных интервалов для параметров уравнения с установленной вероятностью (указана как Level of Confidence в верхнем поле таблицы).
Соответственно уравнение линейно модели тренда имеет вид .
После этого возвращаемся к анализу и нажимаем на кнопку Analysis of Variance (дисперсионный анализ) на той же закладке Quick (см. рис. 3.16).

Рис. 3.18. Результаты дисперсионного анализа линейной модели тренда
В верхней заголовочной строке таблицы выдаются пять оценок:
Sum of Squares – сумма квадратов отклонений; df – число степеней свободы; Mean Squares – средний квадрат; F-value – критерий Фишера; p-value – расчетный уровень значимости F -критерия.
В левом столбце указывается источник вариации:
Regression – вариация, объясненная уравнением тренда; Residual – вариация остатков – отклонений фактических значений от выровненных (полученных по уравнению тренда); Total – общая вариация переменной.
На пересечении столбцов и строк получаем однозначно определенные показатели, расчетные формулы для которых представлены в табл. 3.2,
Таблица 3.2
Расчет показателей вариации трендовых моделей
| Source | df | Sum of Squares | Mean squares | F-value |
| Regression | m |  |  |  |
| Residual | n-m |  |  | |
| Total | n |  | ||
| Corrected Total | n-1 |  |  | |
| Regresion vs. Corrected Total | m | SSR | MSR |  |
где – выровненные значения уровней динамического ряда; – фактические значения уровней динамического ряда; – среднее значение уровней динамического ряда.
SSR (Regression Sum of Squares) – сумма квадратов прогнозных значений; SSE (Residual Sum of Squares) – сумма квадратов отклонений теоретических и фактических значений (для расчета остаточной, необъясненной дисперсии); SST (TotalSum of Squares) – сумма первой и второй строчки (сумма квадратов фактических значений); SSCT (Corrected TotalSum of Squares) – сумма квадратов отклонений фактических значений от средней величины (для расчета общей дисперсии); Regression vs. Corrected Total Sum of Squares – повторение первой строчки; MSR (Regression Mean Squares) – объясненная дисперсия; MSE (Residual Mean Squares) – остаточная, необъясненная дисперсия; MSCT (Mean Squares Corrected Total) – скорректированная общая дисперсия; Regression vs. Corrected Total Mean Squares – повторение первой строчки; Regression F-value – расчетное значение F -критерия; Regression vs. Corrected Total F-value – скорректированное расчетное значение F -критерия; n – число уровней ряда; m – число параметров уравнения тренда.
Далее опять же на закладке Quick (см. рис. 3.16) нажимаем кнопку Predicted values, Residuals, etc . После ее нажатия система строит таблицу, состоящую из трех столбцов (рис. 3.19).
Observed – наблюдаемые значения (то есть уровни исходного динамического ряда);
Тренд - это закономерность описывающая подъем или падение показателя в динамике. Если изобразить любой динамический ряд (статистические данные, представляющие собой список зафиксированных значений изменяемого показателя во времени) на графике, часто выделяется определенный угол – кривая либо постепенно идет на увеличение или на уменьшение, в таких случаях принято говорить, что ряд динамики имеет тенденцию (к росту или падению соответственно).
Тренд как модель
Если же построить модель, описывающую это явление, то получается довольно простой и очень удобный инструмент для прогнозирования не требующий каких-либо сложных вычислений или временных затрат на проверку значимости или адекватности влияющих факторов.
Итак, что же собой представляет тренд как модель? Это совокупность расчетных коэффициентов уравнения, которые выражают регрессионную зависимость показателя (Y) от изменения времени (t). То есть, это точно такая же регрессия, как и те, что мы рассматривали ранее, только влияющим фактором здесь выступает именно показатель времени.
Важно!
В расчетах под t обычно подразумевается не год, номер месяца или недели, а именно порядковый номер периода в изучаемой статистической совокупности – динамическом ряде. К примеру, если динамический ряд изучается за несколько лет, а данные фиксировались ежемесячно, то использовать обнуляющуюся нумерацию месяцев, с 1 по 12 и опять сначала, в корне неверно. Также неверно в случае, если изучение ряда начинается, к примеру, с марта месяца в качестве значения t использовать 3 (третий месяц в году), если это первое значение в изучаемой совокупности, то его порядковый номер должен быть 1.
Модель линейного тренда
Как и любая другая регрессия, тренд может быть как линейным (степень влияющего фактора t равна 1) так и нелинейным (степень больше или меньше единицы). Так как линейная регрессия является самой простейшей, хотя далеко не всегда самой точной, то рассмотрим более детально именно этот тип тренда.
Общий вид уравнения линейного тренда:
Y(t) = a 0 + a 1 *t + Ɛ
Где a 0 – это нулевой коэффициент регрессии, то есть, то каким будет Y в случае, если влияющий фактор будет равен нулю, a 1 – коэффициент регрессии, который выражает степень зависимости исследуемого показателя Y от влияющего фактора t, Ɛ – случайная компонента или стандартная ошибка, по сути являет собой разницу между реально существующими значениями Y и расчетными. t – это единственный влияющий фактор – время.
Чем более выраженная тенденция роста показателя или его падения, тем будет больше коэффициент a 1 . Соответственно, предполагается, что константа a 0 совместно со случайной компонентой Ɛ отражают остальные регрессионные влияния, помимо времени, то есть всех прочих возможных влияющих факторов.
Рассчитать коэффициенты модели можно стандартным Методом наименьших квадратов (МНК). Со всеми этими расчетами Microsoft Excel справляется на ура самостоятельно, при чем, чтобы получить модель линейного тренда либо готовый прогноз существует целых пять способов, которые мы по отдельности разберем ниже.
Графический способ получения линейного тренда
В этом и во всех дальнейших примерах будем использовать один и тот же динамический ряд – уровень ВВП, который вычисляется и фиксируется ежегодно, в нашем случае исследование будет проходить на периоде с 2004-го по 2012-й гг.

Добавим к исходным данным еще один столбец, который назовем t и пометим цифрами по возрастающей порядковые номера всех зафиксированных значений ВВП за указанный период с 2004-го по 2012-й гг. – 9 лет или 9 периодов .

Эксель добавит пустое поле – разметку под будущий график, выделяем этот график и активируем появившуюся вкладку в панели меню – Конструктор , ищем кнопку Выбрать данные , в отрывшемся окне жмем кнопочку Добавить . Всплывшее окошко предложит выбрать данные для построения диаграммы. В качестве значения поля Имя ряда выбираем ячейку, которая содержит текст, наиболее полно отвечающий названию графика. В поле Значения X указываем интервал ячеек стобца t – влияющего фактора. В поле Значения Y указываем интервал ячеек столбца с известными значениями ВВП (Y) – исследуемого показателя.

Заполнив указанные поля, несколько раз нажимаем кнопку ОК и получаем готовый график динамики. Теперь выделяем правой кнопкой мыши саму линию графика и из появившегося контекстного меню выбираем пункт Добавить линию тренда

Откроется окошко для настройки параметров построения линии тренда, где среди типов моделей выбираем Линейная , ставим галочки напротив пунктов Показывать уравнение на диаграмме и Поместить на диаграмму величину достоверности аппроксимации R2 , этого будет достаточно чтобы на графике отобразилась уже построенная линия тренда, а также математический вариант отображения модели в виде готового уравнения и показатель качества модели R 2 . Если вас интересует отображение на графике прогноза, чтобы визуально оценить отрыв исследуемого показателя укажите в поле Прогноз вперед на количество интересующих периодов.

Собственно это все, что касается этого способа, можно конечно добавить, что отображаемое уравнение линейного тренда это и есть непосредственно сама модель, которую можно использовать, в качестве формулы, чтобы получить расчетные значения по модели и соответственно точные значения прогноза (прогноз отображаемый на графике, оценить можно лишь приблизительно), что мы и сделали в приложенному к статье примере.
Построение линейного тренда с помощью формулы ЛИНЕЙН

Суть этого метода сводится к поиску коэффициентов линейного тренда с помощью функции ЛИНЕЙН , затем, подставляя эти влияющие коэффициенты в уравнение, получим прогнозную модель.
Нам потребуется выделить две рядом стоящие ячейки (на скриншоте это ячейки A38 и B38), далее в строке формул вверху (выделено красным на скриншоте выше) вызываем функцию, написав «=ЛИНЕЙН(», после чего эксель выведет подсказки того, что требуется для этой функции, а именно:
- выделяем диапазон с известными значениями описываемого показателя Y (в нашем случае ВВП, на скриншоте диапазон выделен синим) и ставим точку с запятой
- указываем диапазон влияющих факторов X (в нашем случае это показатель t, порядковый номер периодов, на скриншоте выделено зеленым) и ставим точку с запятой
- следующий по порядку требуемый параметр для функции – это определение того нужно ли рассчитывать константу, так как мы изначально рассматриваем модель с константой (коэффициент a 0 ), то ставим либо «ИСТИНА» либо «1» и точку с запятой
- далее нужно указать требуется ли расчет параметров статистики (в случае, если бы мы рассматривали этот вариант, то изначально пришлось бы выделить диапазон «под формулу» на несколько строк ниже). Указывать необходимость расчета параметров статистики, а именно стандартного значение ошибки для коэффициентов, коэффициента детерминированности, стандартной ошибки для Y, критерия Фишера, степеней свободы и пр. , есть смысл только тогда, когда вы понимаете, что они означают, в этом случае ставим либо «ИСТИНА», либо «1». В случае упрощенного моделирования, которому мы пытаемся научиться, на этом этапе прописывания формулы, ставим «ЛОЖЬ» либо «0» и добавляем после закрывающую скобочку «)»
- чтобы «оживить» формулу, то есть заставить ее работать после прописывания всех необходимых параметров, не достаточно нажать кнопку Enter, необходимо последовательно зажать три клавиши: Ctrl, Shift, Enter

Как видим на скриншоте выше, выделенные нами под формулу ячейки заполнились расчетными значениями коэффициентов регрессии для линейного тренда, в ячейке B38 находится коэффициент a 0 , а в ячейке A38 - коэффициент зависимости от параметра t (или x ), то есть a 1 . Подставляем полученные значения в уравнение линейной функции и получаем готовую модель в математическом выражении – y = 169 572,2+138 454,3*t
Чтобы получить расчетные значения Y по модели и, соответственно, чтобы получить прогноз, нужно просто подставить формулу в ячейку экселя, а вместо t указать ссылку на ячейку с требуемым номером периода (смотрите на скриншоте ячейку D25 ).
Для сравнения полученной модели с реальными данными, можно построить два графика, где в качестве Х указать порядковый номер периода, а в качестве Y в одном случае – реальный ВВП, а, в другом – расчетный (на скриншоте диаграмма справа).
Построение линейного тренда с помощью инструмента Регрессия в Пакете анализа
В статье , по сути, полностью описан этот метод, единственная же разница в том, что в наших исходных данных только один влияющий фактор Х (номер периода – t ).

Как видно на рисунке выше, диапазон данных с известными значениями ВВП выделен как входной интервал Y , а соответствующий ему диапазон с номерами периодов t – как входной интервал Х . Итоги расчетов Пакетом анализа выносятся на отдельный лист и выглядит как набор таблиц (см. рисунок ниже) на котором нас интересуют ячейки, которые были закрашены мною в желтый и зеленый цвета. По аналогии с порядком, расписанным в указанной выше статье, из полученных коэффициентов собирается модель линейного тренда y=169 572,2+138 454,3*t , на основе которой и делаются прогнозы.

Прогнозирование с помощью линейного тренда через функцию ТЕНДЕНЦИЯ
Этот метод отличается от предыдущих тем, что он пропускает необходимые ранее этапы расчета параметров модели и подстановки полученных коэффициентов вручную в качестве формулы в ячейку, чтобы получить прогноз, эта функция как раз и выдает уже готовое рассчитанное прогнозное значение на основе известных исходных данных.

В целевую ячейку (ту ячейку, где хотим видеть результат) ставим знак равно и вызываем волшебную функцию, прописав «ТЕНДЕНЦИЯ(», далее необходимо выделить , то есть , после ставим точку с запятой и выделяем диапазон с известными значениями Х, то есть с номерами периодов t , которые соответствуют столбцу с известными значениями ВВП, опять ставим точку с запятой и выделяем ячейку с номером периода, для которого мы делаем прогноз (правда, в нашем случае, номер периода можно указать не ссылкой на ячейку, а просто цифрой прямо в формуле), далее ставим еще одну точку с запятой и указываем ИСТИНА или 1 , в качестве подтверждения для расчета коэффициента a 0 , наконец, ставим закрывающую скобочку и нажимаем клавишу Enter .
Минус данного метода в том, что он не показывает ни уравнения модели, ни его коэффициентов, из-за чего нельзя сказать, что на основе такой-то модели мы получили такой-то прогноз, также как и нет какого-либо отражения параметров качества модели, того таки коэффициента детерминации, по которому можно было бы сказать имеет ли смысл брать во внимание полученный прогноз или нет.
Прогнозирование с помощью линейного тренда через функцию ПРЕДСКАЗ
Суть данной функции целиком и полностью идентична предыдущей, разница лишь в порядке прописывания исходных данных в формуле и в том, что нет настройки для наличия или отсутствия коэффициента a 0 (то есть функция подразумевает, что этот коэффициент, в любом случае, есть)

Как видно с рисунка выше, в целевую ячейку прописываем «=ПРЕДСКАЗ(» и затем указываем ячейку с номером периода , для которого необходимо просчитать значение по линейному тренду, то есть прогноз, после ставим точку с запятой, далее выделяем диапазон известных значений Y , то есть столбец с известными значениями ВВП , после ставим точку с запятой и выделяем диапазон с известными значениями Х , то есть с номерами периодов t , которые соответствуют столбцу с известными значениями ВВП и, наконец, ставим закрывающую скобочку и жмем клавишу Enter .
Полученные результаты, как и в методе выше, это лишь готовый результат расчета прогнозного значения по линейной трендовой модели, он не выдает ни погрешностей, ни самой модели в математическом выражении.
Подводя итог к статье
Можно сказать, что каждый из методов может быть наиболее приемлемым среди прочих в зависимости от текущей цели, которую мы ставим перед собой. Первые три метода пересекаются между собой как по смыслу, так и по результату, и годятся для любой более или менее серьезной работы, где необходимо описание модели и ее качества. В свою очередь, последние два метода также идентичны между собой и максимально быстро вам дадут ответ, например, на вопрос: «Какой прогноз продаж на следующий год?».









- Пошаговый рецепт с фото и видео Рецепт пряников медовых для рисования
- Мороженое шоколадное: рецепт и фото
- Постный чечевичный суп с грибами
- Диетические блюда из творога с указанием калорий
- Спагетти с чесноком и острым перцем
- К чему снится Снежная Лавина?
- Толкование сна мозоли в сонниках
- Гадание Таро: беременность - онлайн
- Коктейль «Куба Либре» — лучшие рецепты приготовления
- Вина из слив в домашних условиях
- Толкования Густава Миллера
- Как проходит ограничение родительских прав
- Социальные стипендии студентам Стипендия детям инвалидам в вузе
- Особенности вычета на лечение родителей
- Льготы пенсионерам по земельному налогу
- Рецепт: Песочное печенье с джемом - домашнее со сладкой начинкой
- Заправка для борща на зиму, очень вкусные рецепты из свеклы Заготовка для зеленого борща на зиму рецепт
- Ром с соком – беспроигрышный вариант Ром с апельсиновым соком название
- Как приготовить рыбу кижуч
- Слоеный салат «Печенкин Салат печенкин с куриной