Jak obliczyć przedział ufności. Wiele szacunków efektu leczenia
Cel– uczyć studentów algorytmów obliczania przedziałów ufności parametrów statystycznych.
Przy statystycznym przetwarzaniu danych obliczona średnia arytmetyczna, współczynnik zmienności, współczynnik korelacji, kryteria różnicowe i inne statystyki punktowe powinny otrzymać ilościowe granice ufności, które wskazują możliwe wahania wskaźnika w mniejszych i większych kierunkach w obrębie przedziału ufności.
Przykład 3.1
.
Jak ustalono wcześniej, rozkład wapnia w surowicy krwi małp charakteryzuje się następującymi wskaźnikami próbki: = 11,94 mg%;  = 0,127 mg%; N= 100. Należy wyznaczyć przedział ufności dla średniej ogólnej (
= 0,127 mg%; N= 100. Należy wyznaczyć przedział ufności dla średniej ogólnej (  ) z prawdopodobieństwem ufności P
= 0,95.
) z prawdopodobieństwem ufności P
= 0,95.
Średnia ogólna z pewnym prawdopodobieństwem mieści się w przedziale:
 , Gdzie
, Gdzie 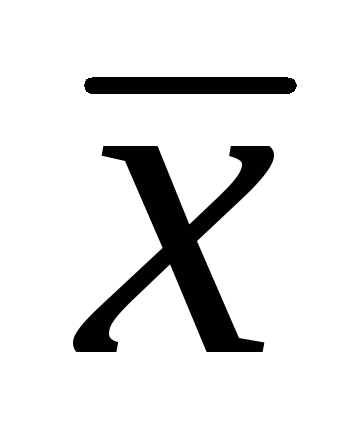 – średnia arytmetyczna próbki; T– Test studenta;
– średnia arytmetyczna próbki; T– Test studenta;  – błąd średni arytmetyczny.
– błąd średni arytmetyczny.
Korzystając z tabeli „Wartości testu t-Studenta” znajdujemy wartość
 z prawdopodobieństwem ufności 0,95 i liczbą stopni swobody k= 100-1 = 99. Jest równe 1,982. Razem z wartościami średniej arytmetycznej i błędu statystycznego podstawiamy to do wzoru:
z prawdopodobieństwem ufności 0,95 i liczbą stopni swobody k= 100-1 = 99. Jest równe 1,982. Razem z wartościami średniej arytmetycznej i błędu statystycznego podstawiamy to do wzoru:
lub 11,69  12,19
12,19
Zatem z prawdopodobieństwem 95% można stwierdzić, że ogólna średnia tego rozkładu normalnego mieści się w przedziale 11,69–12,19 mg%.
Przykład 3.2
. Określ granice 95% przedziału ufności dla wariancji ogólnej (  ) dystrybucja wapnia we krwi małp, jeśli to wiadomo
) dystrybucja wapnia we krwi małp, jeśli to wiadomo  = 1,60, godz N
= 100.
= 1,60, godz N
= 100.
Aby rozwiązać problem, możesz użyć następującej formuły:
Gdzie  – błąd statystyczny rozproszenia.
– błąd statystyczny rozproszenia.
Błąd wariancji próbkowania wyznaczamy za pomocą wzoru:  . Jest równy 0,11. Oznaczający T- kryterium z prawdopodobieństwem ufności 0,95 i liczbą stopni swobody k= 100–1 = 99 jest znane z poprzedniego przykładu.
. Jest równy 0,11. Oznaczający T- kryterium z prawdopodobieństwem ufności 0,95 i liczbą stopni swobody k= 100–1 = 99 jest znane z poprzedniego przykładu.
Skorzystajmy ze wzoru i otrzymajmy:
lub 1,38  1,82
1,82
Dokładniej, przedział ufności wariancji ogólnej można skonstruować za pomocą  (chi-kwadrat) - test Pearsona. Punkty krytyczne dla tego kryterium podano w specjalnej tabeli. Podczas stosowania kryterium
(chi-kwadrat) - test Pearsona. Punkty krytyczne dla tego kryterium podano w specjalnej tabeli. Podczas stosowania kryterium  Do skonstruowania przedziału ufności stosuje się dwustronny poziom istotności. Dla dolnej granicy poziom istotności oblicza się ze wzoru
Do skonstruowania przedziału ufności stosuje się dwustronny poziom istotności. Dla dolnej granicy poziom istotności oblicza się ze wzoru  , na górze –
, na górze –  . Na przykład dla poziomu ufności
. Na przykład dla poziomu ufności  =
0,99
=
0,99 = 0,010,
= 0,010, = 0,990. Odpowiednio, zgodnie z tabelą rozkładu wartości krytycznych
= 0,990. Odpowiednio, zgodnie z tabelą rozkładu wartości krytycznych  , z obliczonymi poziomami ufności i liczbą stopni swobody k= 100 – 1= 99, znajdź wartości
, z obliczonymi poziomami ufności i liczbą stopni swobody k= 100 – 1= 99, znajdź wartości  I
I  . Dostajemy
. Dostajemy  wynosi 135,80, oraz
wynosi 135,80, oraz 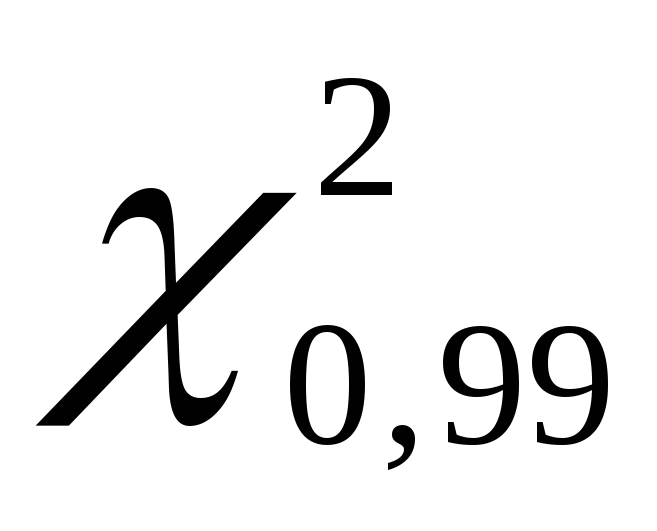 równa się 70,06.
równa się 70,06.
Aby znaleźć granice ufności dla wariancji ogólnej, użyj:  Skorzystajmy ze wzorów: dla dolnej granicy
Skorzystajmy ze wzorów: dla dolnej granicy  , dla górnej granicy
, dla górnej granicy  . Zastąpmy znalezione wartości danymi problemu
. Zastąpmy znalezione wartości danymi problemu  we wzory:
we wzory: 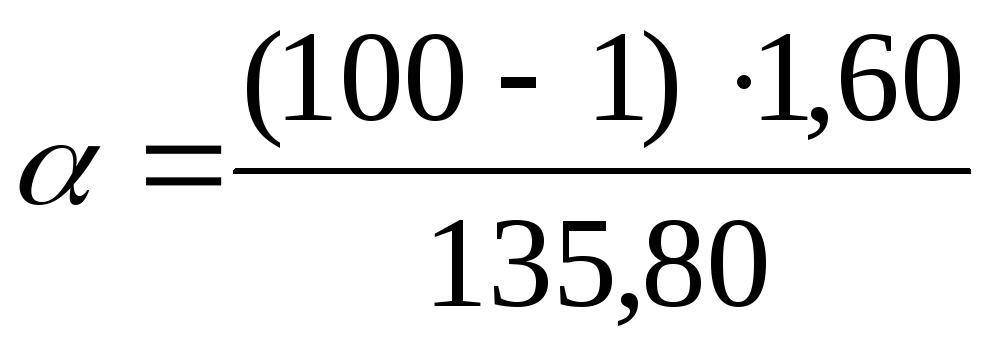 =
1,17;
=
1,17; = 2,26. Zatem z prawdopodobieństwem ufności P= 0,99 lub 99% wariancji ogólnej będzie mieścić się w zakresie od 1,17 do 2,26 mg% włącznie.
= 2,26. Zatem z prawdopodobieństwem ufności P= 0,99 lub 99% wariancji ogólnej będzie mieścić się w zakresie od 1,17 do 2,26 mg% włącznie.
Przykład 3.3 . Spośród 1000 nasion pszenicy z partii przyjętej do elewatora, 120 nasion stwierdzono zakażonych sporyszem. Należy określić prawdopodobne granice ogólnego udziału porażonych nasion w danej partii pszenicy.
Wskazane jest określenie granic ufności udziału ogólnego dla wszystkich jego możliwych wartości za pomocą wzoru:
 ,
,
Gdzie N – liczba obserwacji; M– bezwzględna wielkość jednej z grup; T– odchylenie znormalizowane.
Proporcja próbki zakażonych nasion wynosi  lub 12%. Z prawdopodobieństwem ufnym R= 95% odchylenie znormalizowane ( T-Test studencki o godz k
=
lub 12%. Z prawdopodobieństwem ufnym R= 95% odchylenie znormalizowane ( T-Test studencki o godz k
=
 )T
= 1,960.
)T
= 1,960.
Dostępne dane podstawiamy do wzoru:
Zatem granice przedziału ufności są równe  = 0,122–0,041 = 0,081, czyli 8,1%;
= 0,122–0,041 = 0,081, czyli 8,1%;  = 0,122 + 0,041 = 0,163, czyli 16,3%.
= 0,122 + 0,041 = 0,163, czyli 16,3%.
Zatem z prawdopodobieństwem ufności wynoszącym 95% można stwierdzić, że ogólny odsetek zakażonych nasion mieści się w przedziale od 8,1 do 16,3%.
Przykład 3.4 . Współczynnik zmienności charakteryzujący zmienność wapnia (mg%) w surowicy krwi małp wynosił 10,6%. Rozmiar próbki N= 100. Konieczne jest określenie granic 95% przedziału ufności dla parametru ogólnego Cv.
Granice przedziału ufności dla ogólnego współczynnika zmienności Cv wyznaczane są za pomocą następujących wzorów:
 I
I  , Gdzie K
wartość pośrednia obliczona ze wzoru
, Gdzie K
wartość pośrednia obliczona ze wzoru  .
.
Wiedząc to z prawdopodobieństwem ufności R= 95% odchylenie znormalizowane (test Studenta godz k
=
 )T
= 1,960, najpierw obliczmy wartość DO:
)T
= 1,960, najpierw obliczmy wartość DO:
 .
.
 lub 9,3%
lub 9,3%
 lub 12,3%
lub 12,3%
Zatem ogólny współczynnik zmienności przy 95% poziomie ufności mieści się w przedziale od 9,3 do 12,3%. Przy próbach powtarzanych współczynnik zmienności nie przekroczy 12,3% i nie będzie niższy niż 9,3% w 95 przypadkach na 100.
Pytania do samokontroli:

Problemy do samodzielnego rozwiązania.
1. Średnia zawartość tłuszczu w mleku w okresie laktacji krów mieszańców Kholmogory wynosiła: 3,4; 3,6; 3,2; 3.1; 2,9; 3,7; 3,2; 3,6; 4,0; 3,4; 4.1; 3,8; 3,4; 4,0; 3,3; 3,7; 3,5; 3,6; 3,4; 3.8. Ustal przedziały ufności dla średniej ogólnej na poziomie ufności 95% (20 punktów).
2. Na 400 roślinach żyta mieszańcowego pierwsze kwiaty pojawiały się średnio 70,5 dnia po siewie. Odchylenie standardowe wyniosło 6,9 dnia. Wyznacz błąd średniej i przedziałów ufności dla średniej ogólnej i wariancji na poziomie istotności W= 0,05 i W= 0,01 (25 punktów).
3. Badając długość liści 502 okazów truskawek ogrodowych uzyskano następujące dane:
 = 7,86 cm; σ = 1,32 cm,
= 7,86 cm; σ = 1,32 cm,  =± 0,06 cm Wyznacz przedziały ufności dla średniej arytmetycznej populacji z poziomem istotności 0,01; 0,02; 0,05. (25 punktów).
=± 0,06 cm Wyznacz przedziały ufności dla średniej arytmetycznej populacji z poziomem istotności 0,01; 0,02; 0,05. (25 punktów).
4. W badaniu przeprowadzonym na 150 dorosłych mężczyznach średni wzrost wynosił 167 cm, a σ = 6 cm Jakie są granice średniej ogólnej i ogólnej wariancji przy prawdopodobieństwie ufności 0,99 i 0,95? (25 punktów).
5. Rozkład wapnia w surowicy krwi małp charakteryzuje się następującymi wskaźnikami selektywnymi:
 = 11,94 mg%, σ
= 1,27, N
= 100. Skonstruuj 95% przedział ufności dla średniej ogólnej tego rozkładu. Oblicz współczynnik zmienności (25 punktów).
= 11,94 mg%, σ
= 1,27, N
= 100. Skonstruuj 95% przedział ufności dla średniej ogólnej tego rozkładu. Oblicz współczynnik zmienności (25 punktów).
6. Badano zawartość azotu całkowitego w osoczu krwi szczurów albinosów w wieku 37 i 180 dni. Wyniki wyrażono w gramach na 100 cm3 osocza. W wieku 37 dni 9 szczurów miało: 0,98; 0,83; 0,99; 0,86; 0,90; 0,81; 0,94; 0,92; 0,87. W wieku 180 dni 8 szczurów miało: 1,20; 1,18; 1,33; 1,21; 1,20; 1,07; 1,13; 1.12. Ustaw przedziały ufności dla różnicy na poziomie ufności 0,95 (50 punktów).
7. Wyznaczyć granice 95% przedziału ufności dla ogólnej wariancji rozkładu wapnia (mg%) w surowicy krwi małp, jeżeli dla tego rozkładu wielkość próby wynosi n = 100, błąd statystyczny wariancji próbki S σ 2 = 1,60 (40 punktów).
8. Wyznacz granice 95% przedziału ufności dla ogólnej wariancji rozkładu 40 kłosków pszenicy na długości (σ 2 = 40,87 mm 2). (25 punktów).
9. Za główny czynnik predysponujący do obturacyjnych chorób płuc uważa się palenie tytoniu. Bierne palenie nie jest uważane za taki czynnik. Naukowcy wątpili w nieszkodliwość biernego palenia i badali drożność dróg oddechowych osób niepalących, biernych i aktywnych palaczy. Aby scharakteryzować stan dróg oddechowych, przyjęliśmy jeden ze wskaźników funkcji oddychania zewnętrznego - maksymalne objętościowe natężenie przepływu w połowie wydechu. Spadek tego wskaźnika jest oznaką niedrożności dróg oddechowych. Dane z ankiety przedstawiono w tabeli.
|
Liczba przebadanych osób |
Maksymalne natężenie przepływu środkowo-wydechowego, l/s |
||
|
Odchylenie standardowe |
|||
|
Osoby niepalące |
|||
|
pracować w strefie dla niepalących | |||
|
praca w zadymionym pomieszczeniu | |||
|
Palenie |
|||
|
palić niewielką liczbę papierosów | |||
|
średnia liczba palaczy papierosów | |||
|
palić dużą liczbę papierosów | |||
Korzystając z danych tabeli, znajdź 95% przedziały ufności dla ogólnej średniej i ogólnej wariancji dla każdej grupy. Jakie są różnice pomiędzy grupami? Przedstaw wyniki w formie graficznej (25 punktów).
10. Wyznaczyć granice przedziałów ufności 95% i 99% dla ogólnej wariancji liczby prosiąt w 64 porodach, jeśli błąd statystyczny wariancji próby S σ 2 = 8,25 (30 punktów).
11. Wiadomo, że średnia waga królików wynosi 2,1 kg. Wyznacz granice przedziałów ufności 95% i 99% dla średniej ogólnej i wariancji przy N= 30, σ = 0,56 kg (25 punktów).
12. Zmierzono zawartość ziarna w kłosie dla 100 kłosów ( X), długość ucha ( Y) i masę ziarna w kłosie ( Z). Znajdź przedziały ufności dla średniej ogólnej i wariancji w P 1
= 0,95, P 2
= 0,99, P 3
= 0,999 jeśli
 = 19, = 6,766 cm, = 0,554 g; σ x 2 = 29,153, σ y 2 = 2,111, σ z 2 = 0,064. (25 punktów).
= 19, = 6,766 cm, = 0,554 g; σ x 2 = 29,153, σ y 2 = 2,111, σ z 2 = 0,064. (25 punktów).
13. W 100 losowo wybranych kłosach pszenicy ozimej policzono liczbę kłosków. Próbną populację charakteryzowały następujące wskaźniki:
 = 15 kłosków i σ = 2,28 szt. Określ dokładność, z jaką uzyskano średni wynik (
= 15 kłosków i σ = 2,28 szt. Określ dokładność, z jaką uzyskano średni wynik (  ) i skonstruuj przedział ufności dla średniej ogólnej i wariancji na poziomach istotności 95% i 99% (30 punktów).
) i skonstruuj przedział ufności dla średniej ogólnej i wariancji na poziomach istotności 95% i 99% (30 punktów).
14. Liczba żeber na muszlach mięczaków kopalnych Orthambonity kaligram:
Wiadomo, że N = 19, σ = 4,25. Wyznacz granice przedziału ufności dla średniej ogólnej i ogólnej wariancji na poziomie istotności W = 0,01 (25 punktów).
15. W celu określenia wydajności mlecznej w gospodarstwie mlecznym określono dzienną produkcyjność 15 krów. Według danych za rok każda krowa dawała średnio dziennie następującą ilość mleka (l): 22; 19; 25; 20; 27; 17; 30; 21; 18; 24; 26; 23; 25; 20; 24. Konstruować przedziały ufności dla wariancji ogólnej i średniej arytmetycznej. Czy możemy spodziewać się, że średnioroczna wydajność mleka od krowy wyniesie 10 000 litrów? (50 punktów).
16. W celu ustalenia średniego plonu pszenicy w gospodarstwie rolnym koszono na poletkach próbnych o powierzchni 1, 3, 2, 5, 2, 6, 1, 3, 2, 11 i 2 ha. Wydajność (c/ha) z działek wyniosła 39,4; 38; 35,8; 40; 35; 42,7; 39,3; 41,6; 33; 42; odpowiednio 29. Konstruuj przedziały ufności dla wariancji ogólnej i średniej arytmetycznej. Czy możemy się spodziewać, że średni plon rolniczy wyniesie 42 c/ha? (50 punktów).
W statystyce istnieją dwa rodzaje szacunków: punktowe i przedziałowe. Oszacowanie punktowe to statystyka pojedynczej próby używana do oszacowania parametru populacji. Na przykład średnia próbki jest oceną punktową matematycznych oczekiwań populacji i wariancji próbki S2- punktowa estymacja wariancji populacji σ 2. wykazano, że średnia z próby jest bezstronnym oszacowaniem matematycznych oczekiwań populacji. Średnia próbki nazywana jest bezstronną, ponieważ średnia wszystkich średnich z próby (przy tej samej wielkości próby) N) jest równa matematycznym oczekiwaniom populacji ogólnej.
Aby uzyskać wariancję próbki S2 stała się obiektywnym oszacowaniem wariancji populacji σ 2, mianownik wariancji próbki powinien być równy N – 1 , nie N. Innymi słowy, wariancja populacji jest średnią wszystkich możliwych wariancji próbki.
Szacując parametry populacji należy mieć na uwadze, że statystyki przykładowe takie jak , zależą od konkretnych próbek. Aby wziąć pod uwagę ten fakt, uzyskać estymacja interwałowa matematyczne oczekiwania populacji ogólnej, przeanalizuj rozkład średnich z próby (więcej szczegółów można znaleźć w artykule). Skonstruowany przedział charakteryzuje się pewnym poziomem ufności, który reprezentuje prawdopodobieństwo, że prawdziwy parametr populacji zostanie poprawnie oszacowany. Podobne przedziały ufności można zastosować do oszacowania proporcji cechy R i główna rozproszona masa populacji.
Pobierz notatkę w formacie lub, przykłady w formacie
Konstruowanie przedziału ufności dla oczekiwań matematycznych populacji ze znanym odchyleniem standardowym
Konstruowanie przedziału ufności dla udziału cechy w populacji
W tej sekcji rozszerzono koncepcję przedziału ufności na dane kategoryczne. Pozwala to oszacować udział danej cechy w populacji R przy użyciu przykładowego udziału RS= X/N. Jak wskazano, jeśli ilości NR I N(1 – p) przekracza liczbę 5, rozkład dwumianowy można przybliżyć w sposób normalny. Zatem, aby oszacować udział cechy w populacji R możliwe jest skonstruowanie przedziału, którego poziom ufności jest równy (1 – α)х100%.

Gdzie PS- próbna proporcja cechy równa X/N, tj. liczba sukcesów podzielona przez wielkość próby, R- udział cechy w populacji ogólnej, Z- wartość krytyczna standaryzowanego rozkładu normalnego, N- wielkość próbki.
Przykład 3. Załóżmy, że z systemu informatycznego pobierana jest próba składająca się ze 100 faktur wypełnionych w ciągu ostatniego miesiąca. Załóżmy, że 10 z tych faktur zostało sporządzonych z błędami. Zatem, R= 10/100 = 0,1. Poziom ufności 95% odpowiada wartości krytycznej Z = 1,96.
Zatem prawdopodobieństwo, że od 4,12% do 15,88% faktur zawiera błędy, wynosi 95%.
Dla danej wielkości próby przedział ufności zawierający proporcję cechy w populacji wydaje się szerszy niż w przypadku ciągłej zmiennej losowej. Dzieje się tak, ponieważ pomiary ciągłej zmiennej losowej zawierają więcej informacji niż pomiary danych kategorycznych. Innymi słowy, dane kategoryczne, które przyjmują tylko dwie wartości, zawierają niewystarczającą ilość informacji, aby oszacować parametry ich rozkładu.
Wobliczanie szacunków uzyskanych ze skończonej populacji
Szacowanie oczekiwań matematycznych. Współczynnik korygujący dla populacji końcowej ( fpc) zastosowano w celu zmniejszenia błędu standardowego o współczynnik. Przy obliczaniu przedziałów ufności dla oszacowań parametrów populacji stosuje się współczynnik korygujący w sytuacjach, gdy próbki są pobierane bez zwracania. Zatem przedział ufności dla oczekiwań matematycznych mający poziom ufności równy (1 – α)х100%, oblicza się według wzoru:

Przykład 4. Aby zilustrować zastosowanie współczynnika korygującego dla skończonej populacji, wróćmy do problemu obliczania przedziału ufności dla średniej kwoty faktur, omówionego powyżej w przykładzie 3. Załóżmy, że firma wystawia 5000 faktur miesięcznie i X= 110,27 dolarów, S= 28,95 USD, N = 5000, N = 100, α = 0,05, t 99 = 1,9842. Korzystając ze wzoru (6) otrzymujemy:
Oszacowanie udziału cechy. W przypadku wyboru bez zwrotu, przedział ufności dla proporcji atrybutu mającego poziom ufności równy (1 – α)х100%, oblicza się według wzoru:

Przedziały ufności i kwestie etyczne
Podczas pobierania próbek z populacji i wyciągania wniosków statystycznych często pojawiają się problemy etyczne. Najważniejszym z nich jest zgodność przedziałów ufności i szacunków punktowych statystyk z próby. Publikowanie szacunków punktowych bez określenia powiązanych przedziałów ufności (zwykle na poziomie ufności 95%) i wielkości próby, z której je wyprowadzono, może powodować zamieszanie. Może to wywołać u użytkownika wrażenie, że oszacowanie punktowe jest dokładnie tym, czego potrzebuje do przewidzenia właściwości całej populacji. Dlatego należy zrozumieć, że w każdym badaniu należy skupiać się nie na szacunkach punktowych, ale na szacunkach przedziałowych. Ponadto należy zwrócić szczególną uwagę na prawidłowy dobór wielkości próby.
Najczęściej przedmiotem manipulacji statystycznych są wyniki badań socjologicznych ludności na temat określonych kwestii politycznych. Jednocześnie wyniki badań publikowane są na pierwszych stronach gazet, a błąd losowania i metodologia analiz statystycznych publikowana są gdzieś pośrodku. Aby udowodnić słuszność uzyskanych estymatorów punktowych, należy wskazać liczebność próby, na podstawie której je uzyskano, granice przedziału ufności oraz jego poziom istotności.
Następna notatka
Wykorzystano materiały z książki Levin i in. Statystyka dla menedżerów. – M.: Williams, 2004. – s. 25 448–462
Centralne twierdzenie graniczne stwierdza, że przy wystarczająco dużej próbie rozkład średnich próby można przybliżyć rozkładem normalnym. Właściwość ta nie zależy od rodzaju rozmieszczenia populacji.
Każda próbka daje jedynie przybliżone wyobrażenie o populacji ogólnej, a wszystkie charakterystyki statystyczne próbki (średnia, tryb, wariancja...) są pewnym przybliżeniem lub powiedzmy oszacowaniem ogólnych parametrów, których w większości przypadków nie da się obliczyć ze względu na na niedostępność ogółu społeczeństwa (ryc. 20).
Rysunek 20. Błąd próbkowania
Można jednak określić przedział, w którym z pewnym prawdopodobieństwem mieści się prawdziwa (ogólna) wartość cechy statystycznej. Ten przedział nazywa się D przedział ufności (CI).
Zatem ogólna średnia wartość z prawdopodobieństwem 95% mieści się w tym zakresie
od do, (20)
Gdzie T – wartość tabeli testu Studenta dla α =0,05 i F= N-1
W tym przypadku można również znaleźć 99% CI T wybrany dla α =0,01.
Jakie jest praktyczne znaczenie przedziału ufności?
Szeroki przedział ufności wskazuje, że średnia próbki nie odzwierciedla dokładnie średniej populacji. Dzieje się tak zazwyczaj na skutek niewystarczającej liczebności próby lub jej niejednorodności, tj. duże rozproszenie. Obydwa dają większy błąd średniej i odpowiednio szerszy CI. I to jest podstawa do powrotu do etapu planowania badań.
Górna i dolna granica CI pozwalają oszacować, czy wyniki będą istotne klinicznie
Zatrzymajmy się bardziej szczegółowo nad kwestią statystycznego i klinicznego znaczenia wyników badań właściwości grupowych. Pamiętajmy, że zadaniem statystyki jest wykrycie choćby części różnic w populacjach ogólnych na podstawie danych próbnych. Wyzwaniem dla klinicystów jest wykrycie różnic (a nie tylko różnic), które pomogą w diagnozie lub leczeniu. A wnioski statystyczne nie zawsze są podstawą wniosków klinicznych. Zatem statystycznie istotny spadek stężenia hemoglobiny o 3 g/l nie jest powodem do niepokoju. I odwrotnie, jeśli jakiś problem w organizmie człowieka nie jest powszechny na poziomie całej populacji, nie jest to powód, aby nie zajmować się tym problemem.
|
Spójrzmy na tę sytuację przykład. Naukowcy zastanawiali się, czy chłopcy, którzy cierpieli na jakąś chorobę zakaźną, nie pozostają w tyle za rówieśnikami pod względem wzrostu. W tym celu przeprowadzono badanie reprezentacyjne, w którym wzięło udział 10 chłopców, którzy cierpieli na tę chorobę. Wyniki przedstawiono w tabeli 23. Tabela 23. Wyniki przetwarzania statystycznego
Z obliczeń tych wynika, że średni wzrost 10-letnich chłopców, którzy cierpieli na jakąś chorobę zakaźną, jest zbliżony do normalnego (132,5 cm). Jednakże dolna granica przedziału ufności (126,6 cm) wskazuje, że istnieje 95% prawdopodobieństwo, że rzeczywisty średni wzrost tych dzieci odpowiada pojęciu „niskiego wzrostu”, tj. te dzieci są karłowate. W tym przykładzie wyniki obliczeń przedziału ufności są istotne klinicznie. |
|||||||||||||||||||
Przedziały ufności ( angielski Przedziały ufności) jeden z rodzajów estymatorów przedziałowych stosowanych w statystyce, które obliczane są dla danego poziomu istotności. Pozwalają one na stwierdzenie, że prawdziwa wartość nieznanego parametru statystycznego populacji mieści się w uzyskanym przedziale wartości z prawdopodobieństwem określonym przez wybrany poziom istotności statystycznej.
Rozkład normalny
Gdy znana jest wariancja (σ 2) populacji danych, wynik z można wykorzystać do obliczenia granic ufności (punktów końcowych przedziału ufności). W porównaniu do korzystania z rozkładu t, użycie wyniku z pozwoli na skonstruowanie nie tylko węższego przedziału ufności, ale także bardziej wiarygodnych szacunków wartości oczekiwanej i odchylenia standardowego (σ), ponieważ wynik z jest oparty na rozkład normalny.
Formuła
Do wyznaczenia punktów brzegowych przedziału ufności, pod warunkiem, że znane jest odchylenie standardowe populacji danych, stosuje się następujący wzór
| L = X - Z α/2 | σ |
| √ n |
Przykład
Załóżmy, że wielkość próby wynosi 25 obserwacji, wartość oczekiwana próbki wynosi 15, a odchylenie standardowe populacji wynosi 8. Dla poziomu istotności α=5% wynik Z wynosi Z α/2 =1,96. W takim przypadku będą to dolna i górna granica przedziału ufności
| L = 15 - 1,96 | 8 | = 11,864 |
| √25 |
| L = 15 + 1,96 | 8 | = 18,136 |
| √25 |
Można zatem powiedzieć, że z 95% prawdopodobieństwem matematyczne oczekiwanie populacji będzie mieściło się w przedziale od 11,864 do 18,136.
Metody zawężania przedziału ufności
Załóżmy, że zakres ten jest zbyt szeroki na potrzeby naszych badań. Istnieją dwa sposoby zmniejszenia zakresu przedziału ufności.
- Zmniejsz poziom istotności statystycznej α.
- Zwiększ rozmiar próbki.
Zmniejszając poziom istotności statystycznej do α=10%, otrzymujemy Z-score równy Z α/2 =1,64. W takim przypadku dolna i górna granica przedziału będzie
| L = 15 - 1,64 | 8 | = 12,376 |
| √25 |
| L = 15 + 1,64 | 8 | = 17,624 |
| √25 |
A sam przedział ufności można zapisać jako
W tym przypadku możemy założyć, że z 90% prawdopodobieństwem matematyczne oczekiwanie populacji będzie mieścić się w przedziale .
Jeżeli nie chcemy zmniejszać poziomu istotności statystycznej α, wówczas jedyną alternatywą jest zwiększenie liczebności próby. Zwiększając ją do 144 obserwacji, otrzymujemy następujące wartości granic ufności
| L = 15 - 1,96 | 8 | = 13,693 |
| √144 |
| L = 15 + 1,96 | 8 | = 16,307 |
| √144 |
Sam przedział ufności będzie miał następującą postać
Zatem zawężenie przedziału ufności bez zmniejszania poziomu istotności statystycznej jest możliwe jedynie poprzez zwiększenie liczebności próby. Jeżeli zwiększenie liczebności próby nie jest możliwe, zawężenie przedziału ufności można osiągnąć jedynie poprzez zmniejszenie poziomu istotności statystycznej.
Konstruowanie przedziału ufności dla rozkładu innego niż normalny
Jeżeli odchylenie standardowe populacji nie jest znane lub rozkład różni się od normalnego, do skonstruowania przedziału ufności wykorzystuje się rozkład t. Technika ta jest bardziej konserwatywna, co znajduje odzwierciedlenie w szerszych przedziałach ufności w porównaniu z techniką opartą na wskaźniku Z-score.
Formuła
Aby obliczyć dolną i górną granicę przedziału ufności na podstawie rozkładu t, należy skorzystać z poniższych wzorów
| L = X - t α | σ |
| √ n |
Rozkład Studenta, czyli rozkład t, zależy tylko od jednego parametru – liczby stopni swobody, która jest równa liczbie poszczególnych wartości atrybutu (liczbie obserwacji w próbie). Wartość testu t-Studenta dla danej liczby stopni swobody (n) oraz poziom istotności statystycznej α można znaleźć w tabelach referencyjnych.
Przykład
Załóżmy, że liczebność próby wynosi 25 pojedynczych wartości, wartość oczekiwana próby wynosi 50, a odchylenie standardowe próby wynosi 28. Należy skonstruować przedział ufności dla poziomu istotności statystycznej α=5%.
W naszym przypadku liczba stopni swobody wynosi 24 (25-1), zatem odpowiadająca tabela wartości testu t-Studenta dla poziomu istotności statystycznej α=5% wynosi 2,064. Dlatego będą to dolna i górna granica przedziału ufności
| L = 50 - 2,064 | 28 | = 38,442 |
| √25 |
| L = 50 + 2,064 | 28 | = 61,558 |
| √25 |
A sam przedział można zapisać w formie
Można zatem powiedzieć, że z 95% prawdopodobieństwem matematyczne oczekiwanie populacji będzie mieścić się w przedziale .
Korzystanie z rozkładu t pozwala zawęzić przedział ufności poprzez zmniejszenie istotności statystycznej lub zwiększenie wielkości próby.
Zmniejszając istotność statystyczną z 95% do 90% w warunkach naszego przykładu, otrzymujemy odpowiednią wartość tabelaryczną testu t-Studenta wynoszącą 1,711.
| L = 50 - 1,711 | 28 | = 40,418 |
| √25 |
| L = 50 + 1,711 | 28 | = 59,582 |
| √25 |
W tym przypadku można powiedzieć, że z 90% prawdopodobieństwem matematyczne oczekiwanie populacji będzie mieścić się w przedziale .
Jeśli nie chcemy zmniejszać istotności statystycznej, jedyną alternatywą jest zwiększenie liczebności próby. Powiedzmy, że są to 64 pojedyncze obserwacje, a nie 25 jak w pierwotnym stanie przykładu. Wartość tabelaryczna testu t-Studenta dla 63 stopni swobody (64-1) i poziomu istotności statystycznej α=5% wynosi 1,998.
| L = 50 - 1,998 | 28 | = 43,007 |
| √64 |
| L = 50 + 1,998 | 28 | = 56,993 |
| √64 |
Pozwala to stwierdzić, że z 95% prawdopodobieństwem matematyczne oczekiwanie populacji będzie mieścić się w przedziale .
Duże próbki
Duże próby to próbki z populacji danych, w której liczba pojedynczych obserwacji przekracza 100. Badania statystyczne wykazały, że większe próby mają tendencję do rozkładu normalnego, nawet jeśli rozkład populacji nie jest normalny. Ponadto w przypadku takich próbek zastosowanie wyniku z i rozkładu t daje w przybliżeniu takie same wyniki przy konstruowaniu przedziałów ufności. Zatem w przypadku dużych próbek dopuszczalne jest użycie wyniku z dla rozkładu normalnego zamiast rozkładu t.
Podsumujmy to
Oszacowanie przedziałów ufności
Cele nauczania
Statystyki uwzględniają następujące kwestie dwa główne zadania:
Mamy pewne szacunki oparte na przykładowych danych i chcemy sformułować probabilistyczne stwierdzenie na temat tego, gdzie leży prawdziwa wartość szacowanego parametru.
Mamy konkretną hipotezę, którą należy przetestować na przykładowych danych.
W tym temacie rozważamy pierwsze zadanie. Wprowadźmy jeszcze definicję przedziału ufności.
Przedział ufności to przedział zbudowany wokół szacowanej wartości parametru i pokazujący, gdzie znajduje się prawdziwa wartość szacowanego parametru z określonym z góry prawdopodobieństwem.
Po przestudiowaniu materiału na ten temat:
dowiedzieć się, jaki jest przedział ufności dla oszacowania;
nauczyć się klasyfikować problemy statystyczne;
opanować technikę konstruowania przedziałów ufności, zarówno przy użyciu wzorów statystycznych, jak i przy użyciu narzędzi programowych;
nauczyć się określać wymaganą liczebność próby, aby osiągnąć określone parametry dokładności szacunków statystycznych.
Rozkłady cech próbek
Rozkład T
Jak omówiono powyżej, rozkład zmiennej losowej jest zbliżony do standaryzowanego rozkładu normalnego o parametrach 0 i 1. Ponieważ nie znamy wartości σ, zastępujemy ją jakąś estymatą s. Ilość ma już inny rozkład, a mianowicie lub Dystrybucja studencka, który jest określony przez parametr n -1 (liczba stopni swobody). Rozkład ten jest zbliżony do rozkładu normalnego (im większe n, tym bliższe rozkłady).
Na ryc. 95  przedstawiono rozkład Studenta z 30 stopniami swobody. Jak widać jest on bardzo zbliżony do rozkładu normalnego.
przedstawiono rozkład Studenta z 30 stopniami swobody. Jak widać jest on bardzo zbliżony do rozkładu normalnego.
Podobnie do funkcji pracy z rozkładem normalnym ROZKŁAD NORMALNY i NORMINV, istnieją funkcje do pracy z rozkładem t - ROZKŁAD.T. STUDRASOBR (TINV). Przykład wykorzystania tych funkcji można zobaczyć w pliku STUDRASP.XLS (szablon i rozwiązanie) oraz na rys. 96  .
.
Rozkłady innych cech
Jak już wiemy, aby określić dokładność oszacowania oczekiwań matematycznych, potrzebujemy rozkładu t. Aby oszacować inne parametry, takie jak wariancja, wymagane są różne rozkłady. Dwa z nich to dystrybucja F i x 2 -dystrybucja.
Przedział ufności dla średniej
Przedział ufności- jest to przedział zbudowany wokół szacowanej wartości parametru i pokazujący, gdzie z określonym a priori prawdopodobieństwem znajduje się prawdziwa wartość szacowanego parametru.
Następuje konstrukcja przedziału ufności dla wartości średniej następująco:
Przykład
Restauracja typu fast food planuje poszerzyć swój asortyment o nowy rodzaj kanapki. Aby oszacować popyt na niego, menadżer planuje losowo wybrać 40 gości spośród tych, którzy już go wypróbowali i poprosić ich o ocenę swojego stosunku do nowego produktu w skali od 1 do 10. Menedżer chce oszacować oczekiwane liczbę punktów, jaką otrzyma nowy produkt i skonstruuj 95% przedział ufności dla tego oszacowania. Jak to zrobić? (patrz plik SANDWICH1.XLS (szablon i rozwiązanie).
Rozwiązanie
Aby rozwiązać ten problem, możesz użyć . Wyniki przedstawiono na ryc. 97  .
.
Przedział ufności dla wartości całkowitej
Czasami, korzystając z przykładowych danych, konieczne jest oszacowanie nie oczekiwania matematycznego, ale całkowitej sumy wartości. Na przykład w sytuacji audytora interesem może być oszacowanie nie średniej wielkości konta, ale sumy wszystkich rachunków.
Niech N będzie całkowitą liczbą elementów, n będzie wielkością próby, T 3 będzie sumą wartości w próbie, T” będzie oszacowaniem sumy całej populacji, następnie ![]() , a przedział ufności oblicza się ze wzoru , gdzie s jest oszacowaniem odchylenia standardowego dla próby, a jest oszacowaniem średniej dla próby.
, a przedział ufności oblicza się ze wzoru , gdzie s jest oszacowaniem odchylenia standardowego dla próby, a jest oszacowaniem średniej dla próby.
Przykład
Załóżmy, że agencja podatkowa chce oszacować łączną kwotę zwrotu podatku dla 10 000 podatników. Podatnik albo otrzymuje zwrot podatku, albo płaci dodatkowy podatek. Znajdź 95% przedział ufności dla kwoty zwrotu, zakładając wielkość próby 500 osób (patrz plik KWOTA ZWROTU.XLS (szablon i rozwiązanie).
Rozwiązanie
StatPro nie ma specjalnej procedury w tym przypadku, można jednak zauważyć, że granice można wyznaczyć z granic średniej na podstawie powyższych wzorów (ryc. 98  ).
).
Przedział ufności dla proporcji
Niech p będzie matematycznym oczekiwaniem udziału klientów, a p b będzie oszacowaniem tego udziału uzyskanym z próby o wielkości n. Można to wykazać dla wystarczająco dużych  rozkład ocen będzie zbliżony do normalnego z oczekiwaniem matematycznym p i odchyleniem standardowym
rozkład ocen będzie zbliżony do normalnego z oczekiwaniem matematycznym p i odchyleniem standardowym ![]() . Standardowy błąd oszacowania w tym przypadku wyraża się jako
. Standardowy błąd oszacowania w tym przypadku wyraża się jako  , a przedział ufności wynosi
, a przedział ufności wynosi  .
.
Przykład
Restauracja typu fast food planuje poszerzyć swój asortyment o nowy rodzaj kanapki. Aby ocenić popyt na ten produkt, menadżer wybrał losowo 40 gości spośród tych, którzy już go wypróbowali i poprosił ich o ocenę swojego stosunku do nowego produktu w skali od 1 do 10. Menedżer chce oszacować oczekiwaną proporcję klientów, którzy ocenią nowy produkt na co najmniej 6 punktów (oczekuje, że ci klienci będą konsumentami nowego produktu).
Rozwiązanie
Początkowo tworzymy nową kolumnę na podstawie atrybutu 1 jeśli ocena klienta była większa niż 6 punktów, a w innym przypadku 0 (patrz plik SANDWICH2.XLS (szablon i rozwiązanie).
Metoda 1
Licząc liczbę 1, szacujemy udział, a następnie korzystamy ze wzorów.
Wartość zcr pobierana jest ze specjalnych tabel rozkładu normalnego (na przykład 1,96 dla 95% przedziału ufności).
Stosując to podejście i konkretne dane do skonstruowania przedziału 95%, otrzymujemy następujące wyniki (ryc. 99).  ). Wartość krytyczna parametru zcr wynosi 1,96. Błąd standardowy oszacowania wynosi 0,077. Dolna granica przedziału ufności wynosi 0,475. Górna granica przedziału ufności wynosi 0,775. Menedżer ma więc prawo wierzyć z 95% pewnością, że odsetek klientów oceniających nowy produkt na 6 lub więcej punktów będzie się mieścić w przedziale 47,5–77,5.
). Wartość krytyczna parametru zcr wynosi 1,96. Błąd standardowy oszacowania wynosi 0,077. Dolna granica przedziału ufności wynosi 0,475. Górna granica przedziału ufności wynosi 0,775. Menedżer ma więc prawo wierzyć z 95% pewnością, że odsetek klientów oceniających nowy produkt na 6 lub więcej punktów będzie się mieścić w przedziale 47,5–77,5.
Metoda 2
Ten problem można rozwiązać za pomocą standardowych narzędzi StatPro. Aby to zrobić, wystarczy zauważyć, że udział w tym przypadku pokrywa się ze średnią wartością kolumny Typ. Następnie aplikujemy StatPro/Wnioskowanie statystyczne/Analiza jednej próbki skonstruować przedział ufności średniej (oszacowanie oczekiwań matematycznych) dla kolumny Typ. Wyniki uzyskane w tym przypadku będą bardzo zbliżone do wyników pierwszej metody (ryc. 99).
Przedział ufności dla odchylenia standardowego
s służy jako estymata odchylenia standardowego (wzór podano w rozdziale 1). Funkcja gęstości oszacowania s jest funkcją chi-kwadrat, która podobnie jak rozkład t ma n-1 stopni swobody. Istnieją specjalne funkcje do pracy z tą dystrybucją CHIDIST i CHIINV.
Przedział ufności w tym przypadku nie będzie już symetryczny. Konwencjonalny diagram graniczny pokazano na ryc. 100.
Przykład
Maszyna musi produkować części o średnicy 10 cm, jednak z różnych powodów pojawiają się błędy. Kontrolera jakości niepokoją dwie okoliczności: po pierwsze, średnia wartość powinna wynosić 10 cm; po drugie, nawet w tym przypadku, jeśli odchylenia są duże, wiele części zostanie odrzuconych. Codziennie wykonuje próbkę 50 części (patrz plik KONTROLA JAKOŚCI.XLS (szablon i rozwiązanie). Jakie wnioski może dać taka próbka?
Rozwiązanie
Skonstruujmy 95% przedziały ufności dla średniej i odchylenia standardowego za pomocą StatPro/Wnioskowanie statystyczne/Analiza jednej próbki(ryc. 101  ).
).
Następnie, korzystając z założenia o normalnym rozkładzie średnic, obliczamy odsetek produktów wadliwych, ustalając maksymalne odchylenie na poziomie 0,065. Korzystając z możliwości tabeli podstawieniowej (w przypadku dwóch parametrów) wykreślamy zależność proporcji defektów od wartości średniej i odchylenia standardowego (ryc. 102  ).
).
Przedział ufności dla różnicy między dwiema średnimi
Jest to jedno z najważniejszych zastosowań metod statystycznych. Przykłady sytuacji.
Kierownik sklepu odzieżowego chciałby wiedzieć, ile mniej więcej przeciętna klientka wydaje w sklepie, niż przeciętny mężczyzna.
Obie linie latają na podobnych trasach. Organizacja konsumencka chciałaby porównać różnicę między średnim oczekiwanym czasem opóźnienia lotu w przypadku obu linii lotniczych.
Firma wysyła kupony na określone rodzaje towarów w jednym mieście, a w innym nie. Menedżerowie chcą porównać średnie wolumeny zakupów tych produktów w ciągu najbliższych dwóch miesięcy.
Dealer samochodowy często ma do czynienia z małżeństwami podczas prezentacji. Aby zrozumieć ich osobiste reakcje na prezentację, pary często przeprowadzają oddzielne wywiady. Menedżer chce ocenić różnicę w ocenach wystawianych przez mężczyzn i kobiety.
Przypadek próbek niezależnych
Różnica między średnimi będzie miała rozkład t z n 1 + n 2 - 2 stopniami swobody. Przedział ufności dla μ 1 - μ 2 wyraża się zależnością:

Problem ten można rozwiązać nie tylko za pomocą powyższych formuł, ale także za pomocą standardowych narzędzi StatPro. Aby to zrobić, wystarczy użyć
Przedział ufności dla różnicy proporcji
Niech będzie matematycznym oczekiwaniem udziałów. Niech będą ich przykładowymi szacunkami, skonstruowanymi z próbek o wielkości odpowiednio n 1 i n 2. Następnie następuje oszacowanie różnicy. Dlatego przedział ufności tej różnicy wyraża się jako:
Tutaj zcr jest wartością uzyskaną z rozkładu normalnego przy użyciu specjalnych tabel (na przykład 1,96 dla 95% przedziału ufności).
Standardowy błąd oszacowania wyraża się w tym przypadku zależnością:
 .
.
Przykład
Sklep przygotowując się do dużej wyprzedaży przeprowadził następujące badania marketingowe. Wybrano 300 najlepszych nabywców i losowo podzielono ich na dwie grupy po 150 członków każda. Do wszystkich wybranych klientów wysłano zaproszenia do wzięcia udziału w wyprzedaży, jednak jedynie członkowie pierwszej grupy otrzymali kupon uprawniający do 5% rabatu. Podczas sprzedaży rejestrowano zakupy wszystkich 300 wybranych kupujących. Jak menedżer może zinterpretować wyniki i ocenić skuteczność kuponów? (patrz plik COUPONS.XLS (szablon i rozwiązanie)).
Rozwiązanie
W naszym konkretnym przypadku spośród 150 klientów, którzy otrzymali kupon rabatowy, 55 dokonało zakupu w promocji, a spośród 150, którzy nie otrzymali kuponu, jedynie 35 dokonało zakupu (ryc. 103  ). Wówczas wartości proporcji próbek wynoszą odpowiednio 0,3667 i 0,2333. A różnica próbek między nimi wynosi odpowiednio 0,1333. Zakładając 95% przedział ufności, z tabeli rozkładu normalnego zcr = 1,96. Obliczenie błędu standardowego różnicy próbek wynosi 0,0524. Ostatecznie stwierdzamy, że dolna granica 95% przedziału ufności wynosi odpowiednio 0,0307, a górna granica wynosi odpowiednio 0,2359. Uzyskane wyniki można interpretować w ten sposób, że na każdych 100 klientów, którzy otrzymali kupon rabatowy, możemy spodziewać się od 3 do 23 nowych klientów. Musimy jednak pamiętać, że wniosek ten sam w sobie nie oznacza efektywności wykorzystania kuponów (bo udzielając rabatu tracimy zysk!). Pokażmy to na konkretnych danych. Załóżmy, że średni rozmiar zakupu wynosi 400 rubli, z czego 50 rubli. sklep ma zysk. Wówczas oczekiwany zysk na 100 klientach, którzy nie otrzymali kuponu wynosi:
). Wówczas wartości proporcji próbek wynoszą odpowiednio 0,3667 i 0,2333. A różnica próbek między nimi wynosi odpowiednio 0,1333. Zakładając 95% przedział ufności, z tabeli rozkładu normalnego zcr = 1,96. Obliczenie błędu standardowego różnicy próbek wynosi 0,0524. Ostatecznie stwierdzamy, że dolna granica 95% przedziału ufności wynosi odpowiednio 0,0307, a górna granica wynosi odpowiednio 0,2359. Uzyskane wyniki można interpretować w ten sposób, że na każdych 100 klientów, którzy otrzymali kupon rabatowy, możemy spodziewać się od 3 do 23 nowych klientów. Musimy jednak pamiętać, że wniosek ten sam w sobie nie oznacza efektywności wykorzystania kuponów (bo udzielając rabatu tracimy zysk!). Pokażmy to na konkretnych danych. Załóżmy, że średni rozmiar zakupu wynosi 400 rubli, z czego 50 rubli. sklep ma zysk. Wówczas oczekiwany zysk na 100 klientach, którzy nie otrzymali kuponu wynosi:
50 0,2333 100 = 1166,50 rub.
Podobne wyliczenia dla 100 klientów, którzy otrzymali kupon dają:
30 0,3667 100 = 1100,10 rub.
Spadek średniego zysku do 30 tłumaczy się faktem, że korzystając z rabatu klienci, którzy otrzymali kupon, dokonają zakupu średnio za 380 rubli.
Ostateczny wniosek wskazuje zatem na nieefektywność wykorzystania tego typu kuponów w tej konkretnej sytuacji.
Komentarz. Ten problem można rozwiązać za pomocą standardowych narzędzi StatPro. Aby to zrobić, wystarczy sprowadzić ten problem do problemu oszacowania różnicy pomiędzy dwiema średnimi za pomocą metody, a następnie zastosować StatPro/Wnioskowanie statystyczne/Analiza dwóch próbek skonstruować przedział ufności dla różnicy pomiędzy dwiema wartościami średnimi.
Sterowanie długością przedziału ufności
Długość przedziału ufności zależy od następujące warunki:
dane bezpośrednio (odchylenie standardowe);
poziom istotności;
wielkość próbki.
Wielkość próby do oszacowania średniej
Najpierw rozważmy problem w ogólnym przypadku. Oznaczmy wartość połowy długości podanego nam przedziału ufności jako B (ryc. 104).  ). Wiemy, że przedział ufności dla średniej wartości jakiejś zmiennej losowej X wyraża się jako
). Wiemy, że przedział ufności dla średniej wartości jakiejś zmiennej losowej X wyraża się jako ![]() , Gdzie
, Gdzie ![]() . Wierząc:
. Wierząc:
![]() i wyrażając n, otrzymujemy .
i wyrażając n, otrzymujemy .
Niestety nie znamy dokładnej wartości wariancji zmiennej losowej X. Ponadto nie znamy wartości tcr, ponieważ zależy ona od n poprzez liczbę stopni swobody. W tej sytuacji możemy wykonać następujące czynności. Zamiast wariancji s używamy pewnego oszacowania wariancji w oparciu o wszelkie dostępne implementacje badanej zmiennej losowej. Zamiast wartości t cr używamy wartości z cr dla rozkładu normalnego. Jest to całkiem akceptowalne, ponieważ funkcje gęstości rozkładu dla rozkładu normalnego i t są bardzo zbliżone (z wyjątkiem przypadku małego n). Zatem wymagana formuła ma postać:
 .
.
Ponieważ wzór daje, ogólnie rzecz biorąc, wyniki niecałkowite, za pożądaną wielkość próby przyjmuje się zaokrąglenie z nadmiarem wyniku.
Przykład
Restauracja typu fast food planuje poszerzyć swój asortyment o nowy rodzaj kanapki. Aby ocenić popyt na ten produkt, menedżer planuje losowo wybrać liczbę odwiedzających spośród tych, którzy już go wypróbowali, i poprosić ich o ocenę swojego stosunku do nowego produktu w skali od 1 do 10. Menedżer chce oszacować oczekiwaną liczbę punktów, jaką otrzyma nowy produkt i skonstruuj 95% przedział ufności dla tego oszacowania. Jednocześnie chce, aby połowa szerokości przedziału ufności nie przekraczała 0,3. Z iloma gośćmi musi przeprowadzić wywiad?
wygląda tak:

Tutaj ot jest oszacowaniem proporcji p, a B jest daną połową długości przedziału ufności. Zawyżenie wartości n można uzyskać za pomocą tej wartości ot= 0,5. W tym przypadku długość przedziału ufności nie przekroczy określonej wartości B dla żadnej prawdziwej wartości p.
Przykład
Niech menedżer z poprzedniego przykładu zaplanuje oszacowanie udziału klientów, którzy preferowali nowy typ produktu. Chce skonstruować 90% przedział ufności, którego połowa długości nie przekracza 0,05. Ilu klientów należy uwzględnić w próbie losowej?
Rozwiązanie
W naszym przypadku wartość z cr = 1,645. Dlatego wymaganą ilość oblicza się jako  .
.
Jeżeli menedżer miałby podstawy sądzić, że pożądana wartość p wynosi na przykład około 0,3, to podstawiając tę wartość do powyższego wzoru otrzymalibyśmy mniejszą wartość próbki losowej, a mianowicie 228.
Wzór do ustalenia losowa wielkość próby w przypadku różnicy między dwiema średnimi napisane jako:
 .
.
Przykład
Niektóre firmy komputerowe mają centrum obsługi klienta. W ostatnim czasie wzrosła liczba skarg klientów na złą jakość obsługi. Centrum usług zatrudnia głównie dwa typy pracowników: tych, którzy nie mają dużego doświadczenia, ale ukończyli specjalne kursy przygotowawcze, oraz tych, którzy mają duże doświadczenie praktyczne, ale nie ukończyli specjalnych kursów. Firma chce przeanalizować reklamacje klientów na przestrzeni ostatnich sześciu miesięcy i porównać średnią liczbę reklamacji dla każdej z dwóch grup pracowników. Zakłada się, że liczebność próbek w obu grupach będzie taka sama. Ilu pracowników musi znaleźć się w próbie, aby otrzymać przedział 95% z połową długości nie większą niż 2?
Rozwiązanie
Tutaj σ ots jest oszacowaniem odchylenia standardowego obu zmiennych losowych przy założeniu, że są one bliskie. Zatem w naszym problemie musimy w jakiś sposób uzyskać to oszacowanie. Można to zrobić na przykład w następujący sposób. Analizując dane dotyczące reklamacji klientów w ciągu ostatnich sześciu miesięcy, menedżer może zauważyć, że na jednego pracownika przypada zazwyczaj od 6 do 36 skarg. Wiedząc, że w przypadku rozkładu normalnego prawie wszystkie wartości różnią się od średniej o więcej niż trzy odchylenia standardowe, może zasadnie wierzyć, że:
![]() , skąd σ ots = 5.
, skąd σ ots = 5.
Podstawiając tę wartość do wzoru, otrzymujemy  .
.
Wzór do ustalenia wielkość próby losowej w przypadku szacowania różnicy proporcji ma postać:

Przykład
Niektóre firmy mają dwie fabryki produkujące podobne produkty. Menedżer firmy chce porównać odsetek wadliwych produktów w obu fabrykach. Według dostępnych informacji, wskaźnik defektów w obu fabrykach waha się od 3 do 5%. Ma on na celu skonstruowanie 99% przedziału ufności z połową długości nie większą niż 0,005 (lub 0,5%). Ile produktów należy wybrać z każdej fabryki?
Rozwiązanie
Tutaj p 1ots i p 2ots to szacunki dwóch nieznanych udziałów wad w pierwszej i drugiej fabryce. Jeśli wstawimy p 1ots = p 2ots = 0,5, wówczas otrzymamy zawyżoną wartość dla n. Ponieważ jednak w naszym przypadku mamy informację aprioryczną o tych udziałach, przyjmujemy górne oszacowanie tych udziałów, czyli 0,05. Dostajemy
Podczas szacowania niektórych parametrów populacji na podstawie przykładowych danych przydatne jest nie tylko oszacowanie punktowe parametru, ale także podanie przedziału ufności, który pokazuje, gdzie może znajdować się dokładna wartość szacowanego parametru.
W tym rozdziale zapoznaliśmy się także z zależnościami ilościowymi, które pozwalają nam konstruować takie przedziały dla różnych parametrów; nauczyli się sposobów kontrolowania długości przedziału ufności.
Należy również zauważyć, że problem szacowania wielkości próby (problem planowania eksperymentu) można rozwiązać za pomocą standardowych narzędzi StatPro, a mianowicie StatPro/wnioskowanie statystyczne/wybór wielkości próbki.









- Pożyczka dla przedsiębiorców indywidualnych z zerową sprawozdawczością
- Rolada z mięsa mielonego z jajkami na twardo
- Konfitura morelowa „Pyatiminutka” bez nasion: przygotowana szybko i smacznie
- Pomiar szybkości umysłowej i czasu reakcji
- Jak sprawdzić wyniki ujednoliconego egzaminu państwowego na podstawie danych paszportowych
- Wersja demonstracyjna części ustnej OGE w języku rosyjskim
- Wolfgang Amadeusz Mozart – biografia, zdjęcia, twórczość, życie osobiste kompozytora
- Liczby angielskie z transkrypcją i wymową rosyjską, edukacja, przykłady
- Udomowienie, czyli jak człowiek zmienił zwierzęta
- Prezentacja na temat „Kanada” Slajdy o Kanadzie w języku angielskim
- Czym jest Psałterz i dlaczego warto go czytać?
- Kuskus z jagnięciną i warzywami
- Przepis: Ziemniaki duszone z fasolką szparagową - Z zieleniną Gulasz z fasolki szparagowej z warzywami - przepisy kulinarne
- Zapiekanka ziemniaczana z wątróbką Zapiekanka z wątróbki
- Najsmaczniejsze chude sałatki z kapusty pekińskiej: proste przepisy ze zdjęciami Prosta sałatka z kapustą pekińską i kukurydzą
- Dlaczego marzysz o czerwonej poduszce?
- Pomóż w interpretacji wymarzonej książki
- Wróżenie na fusach kawy
- Owsianka mleczna z wermiszelem
- Jak zrobić domowego szampana z liści winogron