П.15. Решение прикладных задач средствами EXCEL. Однофакторный дисперсионный анализ. План-факт анализ в Excel
В MS Excel для проведения однофакторного дисперсионного анализа используется процедура Однофакторный дисперсионный анализ .
Для проведения дисперсионного анализа необходимо:
Ввести данные в таблицу, так чтобы в каждом столбце оказались данные, соответствующие одному значению исследуемого фактора, а столбцы располагались в порядке возрастания (убывания) величины исследуемого фактора,
Выполнить команду Сервис > Анализ данных;
В появившемся диалоговом окне Анализ данных в списке Инструменты анализа выбрать процедуру Однофакторный дисперсионный анализ, указав курсором мыши и щелкнув левой кнопкой мыши. Затем нажать кнопку ОК;
В появившемся диалоговом окне задать Входной интервал, то есть ввести ссылку на диапазон анализируемых данных, содержащий все столбцы данных. Для этого следует навести указатель мыши на верхнюю левую ячейку диапазона данных, нажать левую кнопку мыши и, не отпуская ее, протянуть указатель мыши к нижней правой ячейке, содержащей анализируемые данные, затем отпустить левую кнопку мыши;
В разделе Группировка переключатель установить в положение по столбцам;
Указать выходной диапазон, то есть ввести ссылку на ячейки, в которые будут выведены результаты анализа. Для этого следует поставить переключатель в положение Выходной интервал (навести указатель мыши и щелкнуть левой кнопкой), далее навести указатель мыши на правое поле ввода Выходной интервал и щелкнуть левой кнопкой мыши, затем указатель мыши навести на левую верхнюю ячейку выходного диапазона и щелкнуть левой кнопкой мыши. Размер выходного диапазона будет определен автоматически, и на экран будет выведено сообщение в случае возможного наложения выходного диапазона на исходные данные.
Нажать кнопку ОК.
Результаты анализа. Выходной диапазон будет включать в себя результаты дисперсионного анализа: средние, дисперсии, критерий Фишера и другие показатели.
Интерпретация результатов. Влияние исследуемого фактора определяется по величине значимости критерия Фишера, которая находится в таблице Дисперсионный анализ на пересечении строки Между группами и столбца Р-Значение . В случаях, когда Р-Значение < 0,05, критерий Фишера значим, и влияние исследуемого фактора можно считать доказанным.
Задача №1.
Изучалось различие в продуктивности воспроизведения одного и того же материала трех групп испытуемых (по 5 человек), различающихся условиями предъявления этого материала для запоминания. Результаты обследования приведены в таблице.
|
№ |
Условие 1 |
Условие 2 |
Условие 3 |
|
11 |
|||
|
10 |
|||
Проверить гипотезу о том, что продуктивность воспроизведения материала зависит от условий его предъявления.
Решение:
Формулируем гипотезы:
H – продуктивность воспроизведения материала не зависит от условий его предъявления.
H – продуктивность воспроизведения материала зависит от условий его предъявления.
1. Исследуемые данные введите в рабочую таблицу Excel по столбцам: в столбец А - данные по Условию 1, в столбец В - данные по Условию 2, в столбец С – данные по Условию 3 (диапазон А1-С6 ).
2. Выполните команду Сервис Анализ данных. В появившемся диалоговом окне Анализ данных в списке Инструменты анализа щелчком мыши выберите процедуру Однофакторный дисперсионный анализ. Нажмите кнопку ОК.
3. В появившемся диалоговом окне Однофакторный дисперсионный анализ в поле Входной интервал задайте А2-С6. Для этого наведите указатель мыши на ячейку А2 и протяните его к ячейке С6 при нажатой левой кнопке мыши.
4. В разделе Группировка переключатель установите в положение по столбцам.
5. Далее необходимо указать выходной диапазон. Для этого поставьте переключатель в положение Выходной интервал (наведите указатель мыши и щелкните левой кнопкой), затем щелкните указателем мыши в правом поле ввода Выходной интервал, и щелчком мыши на ячейке А8 укажите расположение выходногодиапазона. Нажмите кнопку ОК.
Результаты анализа. В результате будет получена таблица, показанная на рис. 5.
|
Условие 1 |
Условие 2 |
Условие 3 |
||||
|
Однофакторный дисперсионный анализ |
||||||
|
ИТОГИ |
||||||
|
Группы |
Счет |
Сумма |
Среднее |
Дисперсия |
||
|
Столбец 1 |
25 |
2,5 |
||||
|
Столбец 2 |
35 |
2,5 |
||||
|
Столбец 3 |
45 |
2,5 |
||||
|
Дисперсионный анализ |
||||||
|
Источник вариации |
SS |
df |
MS |
F |
P-Значение |
F критическое |
|
Между группами |
40 |
20 |
0,0061964 |
3,885290312 |
||
|
Внутри групп |
30 |
12 |
2,5 |
|||
|
Итого |
70 |
14 |
||||
|
Рисунок |
||||||
Интерпретация результатов. В таблице Дисперсионный анализ на пересечении строки Между группами и столбца Р-Значение находится величина 0,000729 . Величина Р-Значение < 0,01 , следовательно, критерий Фишера значим, и обнаружено статистически достоверное влияние условий предъявления материала на продуктивность его воспроизведения.
Задача №2.
Для проверки влияния громкости сигнала на скорость реакции случайным образом отобрали 3 группы испытуемых. Первой группе (5 человек) предъявляли звуковой сигнал в 10 дБ, второй (6 человек) – 30 дБ, третьей (4 человека) – 50 дБ. У испытуемых каждой группы фиксировали время реакции в миллисекундах.
Сформулировать гипотезу по данным условия и проверить ее.
|
Номер группы |
1 |
2 |
3 |
|
Результаты измерений |
304 268 272 262 283 |
272 264 256 269 285 247 |
223 184 209 183 |
Задача №3.
Психолог-консультант для каждого сотрудника фирмы с помощью опросника К. Томаса определил стратегии поведения в конфликтных ситуациях, зафиксировав уровень образования (1 – среднее; 2 – среднее специальное; 3 – высшее) и должностной статус (1 – исполнитель; 2 – менеджер младшего звена; 3 – менеджер среднего звена).
Задание 1. Можно ли утверждать, что фактор уровня образования и должностной статус влияют на уровень стратегии поведения в конфликте, и если – да, каков уровень этого влияния для каждой стратегии?
Задание 2. Оценить совместное влияние уровня образования и должностного статуса на стратегии поведения в конфликте.
|
№ |
Образ. |
Соперн. |
Сотруд. |
Избег. |
Присп. |
Компр. |
Должн. статус |
|
10 |
|||||||
|
10 |
|||||||
|
11 |
10 |
||||||
|
12 |
|||||||
|
13 |
|||||||
|
14 |
10 |
||||||
|
15 |
Здравствуйте, уважаемые посетители блога о статистическом анализе данных. Эта статья является продолжением серии материалов об индексном анализе. Для посетителей, которые здесь впервые, сообщаю, что изучение темы индексов мы начали с общих понятий , затем перешли к анализу динамики с помощью цепных и базисных индексов . После этого приступили к освоению метода индексного анализа данных. Данный метод в большей мере раскрывается при анализе мультипликативных экономико-математических моделей, о чем также была . После обзора философской основы методологии, мы приступили к рассмотрению влияния индивидуальных индексов на агрегатный . Сегодня мы возьмемся за абсолютное влияние факторных показателей.
Дабы не тратить время зря, не будем повторять все, что уже было рассмотрено ранее. Пропустившим материал рекомендую перейти по ссылкам выше – это важно для понимания того, что будет написано ниже. Повторюсь только, что основная цель индексного анализа – это разложение динамики результативного показателя на составляющие элементы, которые соответствуют динамике факторных показателей.
В случае с относительным влиянием все просто. Агрегатный индекс состоит из произведения индивидуальных индексов в правой части уравнения. Здесь хоть так крути, хоть этак – все одинаково – от перемены мест множителей произведение не меняется. Поэтому вклад каждого «фактора» равен самому индивидуальному индексу.
Однако изменение результативного показателя может быть не только относительным, но и абсолютным. Абсолютное изменение результата очень легко рассчитать, взяв разницу уровней в отчетном и базисном периодах. В нашем примере со стоимостью абсолютное изменение результативного показателя можно рассчитать так:
Где, ∆w – это абсолютное изменение стоимости, w 1 и w 0 – значения стоимости продаж в отчетном и базисном периодах соответственно; p и q – цены и количество.
Таким образом рассчитывается абсолютное изменение результативного показателя. Чтобы определить вклад факторных показателей, нужно разбить эту величину на части в некотором соответствии с их динамикой. Как же? Просто сложить или перемножить индексы уже не получится. Давайте посмотрим, что нам предлагает статистика. Дабы не воспарить в просторы абстракций, рассмотрим все на нашем примере.
Методика расчета абсолютного влияния факторных признаков заключается в том, чтобы зафиксировать все показатели в правой части индексной модели кроме одного (анализируемого), и посмотреть, что произойдет с результатом. Другими словами, все факторные показатели фиксируются на определенном уровне, а вместо анализируемого «фактора» берется разность его значений в отчетом и базисном периодах. Такова идея, причем правильная. Однако сразу возникает вопрос: на каком уровне фиксировать веса, то есть остальные показатели модели? Можно на отчетом, можно на базисном. Как поступить? Давайте я сейчас продемонстрирую, к чему приводят различные варианты выбор весов. Тогда лучше запомнится и будет понятней математическая основа.
Допустим, фиксация уровня весов будет на уровне базисного периода, тогда расчет «влияния факторов» будет выглядеть таким образом.
Изменение стоимости «за счет» цены:
Изменение стоимости «за счет» количества:
Что получается? Имеются два «фактора», а также «влияние» каждого из них на результат. Логично, что их сумма должна дать общее изменение. Посмотрим.
Из последнего выражения видно, что сумма «влияний» с базисными весами не дает общее абсолютное изменение результата. Это значит, что разбивка оказалась неправильной, по крайней мере, нарушает логику полного разделения на составляющие.
Попробуем теперь в качестве весов взять отчетный период. Думаю, результат очевиден. Но, чтобы не было сомнений, еще раз напишем вывод, только на этот раз с отчетными весами.
То же самое – не равно.
На самом деле я все знал заранее, а расчет привел специально, чтобы потом не объяснять, зачем используются разные веса. В статистике есть правило для разбивки общего изменения результата таким образом, чтобы сумма составляющих равнялась общему абсолютному изменение результата. Для этого все показатели в правой части делятся на качественные и объемные . Понятия эти растяжимые и строго определения я нигде не встречал. Своими словами можно определить так, что качественные показатели отражают некоторую структуру, эффективность, соотношение и т.п. Объемные показатели измеряются в натуральных единицах и, как правило, не представляют собой какую-либо комбинацию из других показателей. Качественные показатели – это такие, как цена, рентабельность, скорость и проч. Объемные – объем производства, количество товаров, стоимость запасов и проч. Так вот, правило гласит, что для расчета влияния качественных показателей используются отчетные веса (у объемных показателей), а для расчета влияния объемных показателей используются базисные веса (у качественных показателей). В нашем примере цена – это качественный показатель, количество проданных товаров – объемный.
Тогда абсолютное изменение стоимости «за счет» цены будет:
Абсолютное изменение стоимости «за счет» количества:
Несложно убедиться, что их сумма даст общее изменение результата:
Таковы общие правила. Хотя они не являются строгими. В некоторых учебниках написано, что веса можно взять в обратном порядке. То есть базисные для качественных и отчетные для объемных. Можно взять и среднее между отчетным и базисным значением. Главное, чтобы сумма «влияний» дала общее абсолютное изменение результативного показателя.
Как видим, здесь уже не все так однозначно, как с простым сопоставлением индексов. Индивидуальный индекс приравнивается к величине его влияния на результат и точка. Вариантов больше нет. В анализе абсолютного влияния разницу анализируемого факторного показателя можно умножить на отчетные веса, на базисные или на средние. И результат получится везде разный. Традиционно используется вышеописанный вариант, но я предлагаю вновь обратиться к конкретному примеру и к буквальной, а не шаблонной, трактовке. Это позволит нам уловить суть различий и при необходимости самостоятельно принимать решение, какой вариант выбрать.
Давайте рассмотрим эти три варианта на нашем примере двухфакторной индексной модели. Первый вариант – классический. Рассмотрим еще раз формулу «влияния» цены:
Видно, что вес (количество) фиксируется на уровне отчетного периода. Получается, что если допустить, что количество продаваемых товаров в базисном периоде было, как в отчетном, то изменение цены привело бы к изменению стоимости на величину, которая рассчитывается по обозначенной формуле. Однако логичнее сделать допущение, что какое-то обстоятельство или условие не изменилось, чем изменилось заранее, как мы только что сделали. Мягко говоря, допущение какое-то потустороннее получилось. Индексный анализ предполагает сравнение отчетного периода с базисным, за основу берется более ранний период. От него и нужно отталкиваться. А в такой трактовке получается, что за основу берутся будущие продажи. Не совсем понятно и как-то не логично. В общем данная формула выглядит весьма подозрительно с точки зрения здравого смысла.
Теперь посмотрим на «влияние» количества:
Если бы цены остались на уровне базисного периода, то динамика стоимости проданных товаров объяснялась бы только изменением количества проданных товаров. Такая трактовка, конечно, весьма логична, так как мы отталкиваемся от базисных условий: и по цене и по уровню продаж.
Итак, получается, что один факторный показатель логично интерпретируется, а другой нет. Хотя и здесь можно поспорить. Вдруг кому-то захочется узнать, что было бы, если бы некоторые изменения произошли раньше, чем это было на самом деле.
Можно попробовать использовать модель с обратным порядком весов, когда для анализа качественных показателей используются базисные веса, а для анализа объемных показателей - отчетные. Не буду расписывать так же подробно, так как ответ очевиден. Ситуация перевернется наоборот. «Влияние» цены будет рассчитано с допущением о количестве продаж в базисном периоде, что в целом логично, а вот «влияние» количества – с условием цен в отчетном периоде, что снова несколько абсурдно.
Есть еще третий вариант – средние веса из отчетного и базисного периодов. В этом варианте я вижу смысл, так как веса не привязываются к какому-либо периоду, а усредненные значение показывают ситуацию на протяжении всего анализируемого периода. С учетом огромного количества погрешностей и допущений в индексном анализе, такая трактовка вполне логична. Однако конкретный вариант следует выбирать из конкретных условий. Невозможно задать общие правила.
Хочу отметить еще один полезный нюанс. Как я уже написал выше, сумма влияний всех факторных показателей должна дать общее абсолютное изменение результата. В этом заложена математическая логика. Однако на практике может понадобиться проанализировать «влияние» только одно фактора. Например, нас может заинтересовать, как увеличится стоимость в случае увеличения только объемов продаж. Такая постановка задачи на практике часто имеет место. Тогда никакая сумма абсолютных влияний не проверятся и можно выбрать только одну формулу с нужным весом. Из примеров выше мы видели, что лучше брать веса в базисном периоде – так логичнее и понятнее.
Материал всегда лучше усваивается, если он наглядный. Сейчас изобразим идею индексного анализа на графике. В предыдущей статье мы отметили, что при геометрической интерпретации результативный показатель в двухфакторной мультипликативной модели – это не что иное, как площадь прямоугольника. Рисунок, напомню, был такой.

Теперь возьмем обозначения из нашего примера со стоимостью и изобразим динамику и влияние факторных показателей на графике. Предположим, что в отчетном периоде цена и количество по сравнению с базисным периодом увеличились. Тогда график динамики результативного показателя примет такой вид.

Следующий пример основан на вымышленных данных, относящихся к изучению удовлетворенности жизнью. Предположим, что вопросник был направлен 100 случайно выбранным взрослым. Вопросник содержал 10 пунктов, предназначенных для определения удовлетворенности на работе, удовлетворенности своим хобби, удовлетворенностью домашней жизнью и общей удовлетворенностью в других областях жизни. Ответы на вопросы были введены в компьютер и промасштабированы таким образом, чтобы среднее для всех пунктов стало равным приблизительно 100.
Результаты были помещены в файл данных Factor.sta. Открыть этот файл можно с помощью опции Файл - Открыть; наиболее вероятно, что этот файл данных находится в директории /Examples/Datasets. Ниже приводится распечатка переменных этого файла (для получения списка выберите Все спецификации переменных в меню Данные).
Цель анализа . Целью анализа является изучение соотношений между удовлетворенностью в различных сферах деятельности. В частности, желательно изучить вопрос о числе факторов, "скрывающихся" за различными областями деятельности и их значимость.
Выбор анализа. Выберите Факторный анализ в меню Анализ - Многомерный разведочный анализ для отображения стартовой панели модуля Факторный анализ. Нажмите на кнопку Переменные на стартовой панели (см. ниже) и выберите все 10 переменных в этом файле.

Другие опции . Для выполнения стандартного факторного анализа в этом диалоговом окне имеется все необходимое. Для получения краткого обзора других команд, доступных из стартовой панели, вы можете выбрать в качестве входного файла корреляционную матрицу (используя поле Файл данных). В поле Удаление ПД вы можете выбрать построчное или попарное исключение или подстановка среднего для пропущенных данных.
Задайте метод выделения факторов. Нажмем теперь кнопку OK для перехода к следующему диалоговому окну с названием Задайте метод выделения факторов. С помощью этого окна диалога вы сможете просмотреть описательные статистики, выполнить множественный регрессионный анализ, выбрать метод выделения факторов, выбрать максимальное число факторов, минимальные собственные значения, а также другие действия, относящиеся к специфике методов выделения факторов. А теперь перейдем во вкладку Описательные.
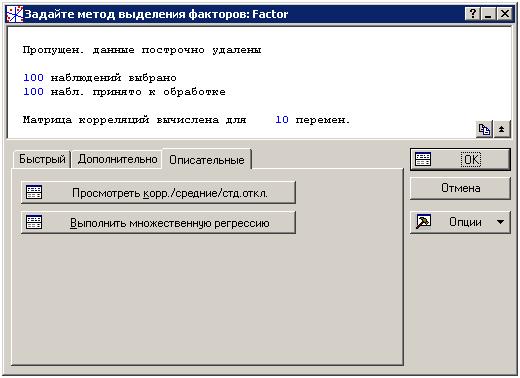
Просмотр описательных статистик. Теперь нажмите на кнопку Просмотреть корр./средние/ст.откл. в этом окне для того, чтобы открыть окно Просмотр описательных статистик.

Теперь вы можете рассмотреть описательные статистики графически или с помощью таблиц результатов.
Вычисление корреляционной матрицы. Нажмите на кнопку Корреляции во вкладке Дополнительно для того, чтобы отобразить таблицу результатов с корреляциями.

Все корреляции в этой таблице результатов положительны, а некоторые корреляции имеют значительную величину. Например, переменные Hobby_1 и Miscel_1 коррелированны на уровне 0.90. Некоторые корреляции (например, корреляции между удовлетворенностью на работе и удовлетворенностью дома) кажутся сравнительно малыми. Это выглядит так, как будто матрица имеет некоторую отчетливую структуру.
Метод выделения. Теперь нажмем кнопку Отмена в диалоговом окне Просмотр описательных статистик для того, чтобы вернуться в диалоговое окно Задайте метод выделения факторов. Вы можете сделать выбор из нескольких методов выделения во вкладке Дополнительно (см. вкладку Дополнительно диалогового окна Задайте метод выделения факторов для описания каждого метода, а также Вводный обзор с описанием метода Главных компонент и метода Главных факторов). В этом примере по умолчанию принимается метод Главных компонент, поле Макс. число факторов содержит значение 10 (максимальное число факторов в этом примере) и поле Мин. собств. значение содержит 0 (минимальное значение для этой команды).

Для продолжения анализа нажмите кнопку OK.
Просмотр результатов. Вы можете просмотреть результаты факторного анализа в окне диалога Результаты факторного анализа. Сначала выберите вкладку Объясненная дисперсия.

Отображение собственных значений . Назначение собственных значений и их полезность для пользователя при принятии решения о том, сколько следует оставить факторов (интерпретировать) были описаны в Вводном обзоре. Теперь нажмем на кнопку Собственные значения, чтобы получить таблицу с собственными значениями, процентом общей дисперсии, накопленными собственными значениями и накопленными процентами.

Как видно из таблицы, собственное значение для первого фактора равно 6.118369; т.е. доля дисперсии, объясненная первым фактором равна приблизительно 61.2%. Заметим, что эти значения случайно оказались здесь легко сравнимыми, так как анализу подвергаются 10 переменных, и поэтому сумма всех собственных значений оказывается равной 10. Второй фактор включает в себя около 18% дисперсии. Остальные факторы содержат не более 5% общей дисперсии. Выбор числа факторов. В разделе Вводный обзор кратко описан способ, как полученные собственные значения можно использовать для решения вопроса о том, сколько факторов следует оставить в модели. В соответствии с критерием Кайзера (Kaiser, 1960), вы должны оставить факторы с собственными значениями большими 1. Из приведенной выше таблицы следует, что критерий приводит к выбору двух факторов.
Критерий каменистой осыпи . Теперь нажмите на кнопку График каменистой осыпи, чтобы получить график собственных значений с целью применения критерия осыпи Кэттеля (Cattell, 1966). График, представленный ниже, был дополнен отрезками, соединяющими соседние собственные значения, чтобы сделать критерий более наглядным. Кэттель (Cattell) утверждает, основываясь на методе Монте-Карло, что точка, где непрерывное падение собственных значений замедляется и после которой уровень остальных собственных значений отражает только случайный "шум". На графике, приведенном ниже, эта точка может соответствовать фактору 2 или 3 (как показано стрелками). Поэтому испытайте оба решения и посмотрите, которое из них дает более адекватную картину.

Теперь рассмотрим факторные нагрузки.
Факторные нагрузки . Как было описано в разделе Вводный обзор, факторные нагрузки можно интерпретировать как корреляции между факторами и переменными. Поэтому они представляют наиболее важную информацию, на которой основывается интерпретация факторов. Сначала посмотрим на (неповернутые) факторные нагрузки для всех десяти факторов. Во вкладке Нагрузки диалогового окна Результаты факторного анализа в поле Вращение факторов зададим значение без вращения и нажмем на кнопку Факторные нагрузки для отображения таблицы нагрузок.

Вспомним, что выделение факторов происходило таким образом, что последующие факторы включали в себя все меньшую и меньшую дисперсию (см. раздел Вводный обзор). Поэтому не удивительно, что первый фактор имеет наивысшую нагрузку. Отметим, что знаки факторных нагрузок имеют значение лишь для того, чтобы показать, что переменные с противоположными нагрузками на один и тот же фактор взаимодействуют с этим фактором противоположным образом. Однако вы можете умножить все нагрузки в столбце на -1 и обратить знаки. Во всем остальном результаты окажутся неизменными.
Вращение факторного решения. Как описано в разделе Вводный обзор, действительная ориентация факторов в факторном пространстве произвольна, и всякое вращение факторов воспроизводит корреляции так же хорошо, как и другие вращения. Следовательно, кажется естественным повернуть факторы таким образом, чтобы выбрать простейшую для интерпретации факторную структуру. Фактически, термин простая структура был придуман и определен Терстоуном (Thurstone, 1947) главным образом для описания условий, когда факторы отмечены высокими нагрузками на некоторые переменные и низкими - для других, а также когда имеются несколько больших перекрестных нагрузок, т.е. имеется несколько переменных с существенными нагрузками на более чем один фактор. Наиболее стандартными вычислительными методами вращения для получения простой структуры является метод вращения варимакс, предложенный Кайзером (Kaiser, 1958). Другими методами, предложенными Харманом (Harman, 1967), являются методы квартимакс, биквартимакс и эквимакс (см. Harman, 1967).
Выбор вращения . Сначала рассмотрим количество факторов, которое вы желаете оставить для вращения и интерпретации. Ранее было решено, что наиболее правдоподобным и приемлемым числом факторов является два, однако на основе критерия осыпи было решено учитывать также и решение с тремя факторами. Нажмите на кнопку Отмена для того, чтобы возвратиться в окно диалога Задайте метод выделения факторов, и измените поле Максимальное число факторов во вкладке Быстрый с 10 на 3, затем нажмите кнопку OK для того, чтобы продолжить анализ.
Теперь выполним вращение по методу варимакс. Во вкладке Нагрузки диалогового окна Результаты факторного анализа в поле Вращение факторов установите значение Варимакс исходных.

Нажмем кнопку Факторные нагрузки для отображения в таблице результатов получаемых факторных нагрузок.

Отображение решения при вращении трех факторов. В таблице приведены существенные нагрузки на первый фактор для всех переменных, кроме относящихся к дому. Фактор 2 имеет довольно значительные нагрузки для всех переменных, кроме переменных связанных с удовлетворенностью на работе. Фактор 3 имеет только одну значительную нагрузку для переменной Home_1. Тот факт, что на третий фактор оказывает высокую нагрузку только одна переменная, наводит на мысль, а не может ли получиться такой же хороший результат без третьего фактора?
Обозрение решения при вращении двух факторов . Снова нажмите на кнопку Отмена в окне диалога Результаты факторного анализа для того, чтобы возвратиться к диалоговому окну Задайте метод выделения факторов. Измените поле Максимальное число факторов во вкладке Быстрый с 3 до 2 и нажмите кнопку OK для того, чтобы перейти в диалоговое окно Результаты факторного анализа. Во вкладке Нагрузки в поле Вращение факторов установите значение Варимакс исходных и нажмите кнопку Факторные нагрузки.

Фактор 1, как видно из таблицы, имеет наивысшие нагрузки для переменных, относящихся к удовлетворенности работой. Наименьшие нагрузки он имеет для переменных, относящихся к удовлетворенности домом. Другие нагрузки принимают промежуточные значения. Фактор 2 имеет наивысшие нагрузки для переменных, связанных с удовлетворенностью дома, низшие нагрузки - для удовлетворенности на работе средние нагрузки для остальных переменных.
Интерпретация решения для двухфакторного вращения . Можно ли интерпретировать данную модель? Все выглядит так, как будто два фактора лучше всего идентифицировать как фактор удовлетворения работой (фактор 1) и как фактор удовлетворения домашней жизнью (фактор 2). Удовлетворение своим хобби и различными другими аспектами жизни кажется относящимися к обоим факторам. Эта модель предполагает в некотором смысле, что удовлетворенность работой и домашней жизнью согласно этой выборке могут быть независимыми друг от друга, но оба дают вклад в удовлетворение хобби и другими сторонами жизни.
Диаграмма решения, основанного на вращении двух факторов . Для получения диаграммы рассеяния двух факторов нажмите на кнопку 2М график нагрузок во вкладке Нагрузки диалогового окна Результаты факторного анализа. Диаграмма, показанная ниже, попросту показывает две нагрузки для каждой переменной. Заметим, что диаграмма рассеяния хорошо иллюстрирует два независимых фактора и 4 переменных (Hobby_1, Hobby_2, Miscel_1, Miscel_2) с перекрестными нагрузками.

Теперь посмотрим, насколько хорошо может быть воспроизведена наблюдаемая ковариационная матрица по двухфакторному решению.
Воспроизведенная и остаточная корреляционная матрица. Нажмите на кнопку Воспроизведенные и остаточные корреляции во вкладке Объясненная дисперсия, для того чтобы получить две таблицы с воспроизведенной корреляционной матрицей и матрицей остаточных корреляций (наблюдаемых минус воспроизведенных корреляций).

Входы в таблице Остаточных корреляций могут быть интерпретированы как "сумма" корреляций, за которые не могут отвечать два полученных фактора. Конечно, диагональные элементы матрицы содержат стандартное отклонение, за которое не могут быть ответственны эти факторы и которые равны квадратному корню из единица минус соответствующие общности для двух факторов (вспомним, что общностью переменной является дисперсия, которая может быть объяснена выбранным числом факторов). Если вы тщательно рассмотрите эту матрицу, то сможете увидеть, что здесь фактически не имеется остаточных корреляций, больших 0.1 или меньшие -0.1 (в действительности только малое количество из них близко к этой величине). Добавим к этому, что первые два фактора включают около 79% общей дисперсии (см. накопленный % собственных значений в таблице результатов).
"Секрет" удачного примера . Пример, который вы только что изучили, на самом деле дает решение двухфакторной задачи, близкое к идеальному. Оно определяет большую часть дисперсии, имеет разумную интерпретацию и воспроизводит корреляционную матрицу с умеренными отклонениями (остаточными корреляциями). На самом деле реальные данные редко позволяют получить такое простое решение, и в действительности это фиктивное множество данных было получено с помощью генератора случайных чисел с нормальным распределением, доступного в системе. Специальным образом в данные были "введены" два ортогональных (независимых) фактора, по которым были сгенерированы корреляции между переменными. Этот пример факторного анализа воспроизводит два фактора такими, как они и были, (т.е. фактор удовлетворенности работой и фактор удовлетворенности домашней жизнью). Таким образом, если бы явление (а не искусственные, как в примере, данные) содержало эти два фактора, то вы, выделив их, могли бы кое-что узнать о скрытой или латентной структуре явления.
Другие результаты . Прежде, чем сделать окончательное заключение, дадим краткие комментарии к другим результатам.
Общности . Для получения общностей решения нажмите на кнопку Общности во вкладке Объясненная дисперсия диалогового окна Результаты факторного анализа. Вспомним, что общность переменной - это доля дисперсии, которая может быть воспроизведена при заданном числе факторов. Вращение факторного пространства не влияет на величину общности. Очень низкие общности для одной или двух переменных (из многих в анализе) могут указывать на то, что эти переменные не очень хорошо объяснены моделью.
Коэффициенты значений. Коэффициенты факторов могут быть использованы для вычисления значений факторов для каждого наблюдения. Сами коэффициенты представляет обычно малый интерес, однако факторные значения полезны при проведении дальнейшего анализа. Для отображения коэффициентов нажмите кнопку Коэффициенты значений факторов во вкладке Значения диалогового окна Результаты факторного анализа.
Значения факторов. Факторные значения могут рассматриваться как текущие значения для каждого опрашиваемого респондента (т.е. для каждого наблюдения исходной таблицы данных). Кнопка Значения факторов во вкладке Значения диалогового окна Результаты факторного анализа позволяет вычислить факторные значения. Эти значения можно сохранить для дальнейшего нажатием кнопки Сохранить значения.
Заключительный комментарий. Факторный анализ - это непростая процедура. Всякий, кто постоянно использует факторный анализ со многими (например, 50 или более) переменными, мог видеть множество примеров "патологического поведения", таких, как: отрицательные собственные значения и не интерпретируемые решения, особые матрицы и т.д. Если вы интересуетесь применением факторного анализа для определения или значащих факторов при большом числе переменных, вам следует тщательно изучить какое-либо подробное руководство (например, книгу Хармана (Harman, 1968)). Таким образом, так как многие критические решения в факторном анализе по своей природе субъективны (число факторов, метод вращения, интерпретация нагрузок), будьте готовы к тому, что требуется некоторый опыт, прежде чем вы почувствуете себя уверенным в нем. Модуль Факторный анализ был разработан специально для того, чтобы сделать легким для пользователя интерактивное переключение между различным числом факторов, вращениями и т.д., так чтобы испытать и сравнить различные решения.
Этот пример взят из справочной системы ППП STATISTICA фирмы StatSoft



 Рецепт вкусных сырников с манкой")





- Расклады на картах таро на личность
- Онлайн гадание «Выбор из двух вариантов» на картах Таро с толкованием результата
- Меню для кафе (варианты оформления и образец)
- Великие об успехе. Отступать — всегда рано! Подборка мотивирующих цитат для достижения успеха и своих целей
- Цитаты о бизнесе и успехе великих людей: курс на процветание
- Фирменный бланк ООО и ИП — скачать образцы и как сделать самостоятельно
- Христофор колумб решил что приплыл
- Молитва ангела хранителя сына Ангел хранитель младенца
- Зачем нужны курсы риторики и где их пройти
- Туннельные войны Корея подземная война
- Сильная молитва луке крымскому перед операцией, об исцелении, выздоровлении больного и здравии Молитва луке крымскому после операции
- Осетинский пирог с сыром и зеленью
- Осетинские пироги — лучшие пошаговые рецепты
- Пирожки с тыквой в духовке на дрожжевом, песочном, слоеном тесте
- Идеальные сырники с манкой (всегда держат форму) Рецепт вкусных сырников с манкой
- Сырники из творога с манкой рецепт с фото пошагово на сковороде пышные Рецепт сырников из творога пошагово с манкой
- Вкус Средиземноморья: паста с соусами из баклажан и помидоров
- Мортаделла - итальянская колбаса
- Как приготовить брокколи брокколи с грибами в сметанном соусе Что приготовить из брокколи и грибов
- Как правильно приготовить овсяный суп на плите, в мультиварке и горшочках